Transfer Learning
Principe
*Remarque : * En français, nous dirions plutôt Transfert d’Apprentissage, mais je conserverais le vocabulaire anglais, car la plupart des documents que vous pourrez trouver sur le sujet sont en anglais…
Transfer learning is a machine learning method where a model developed for a task is reused as the starting point for a model on a second task.
Le Transfer Learning est une technique d’apprentissage Automatique dans laquelle un modèle (ici un réseau de neurones), entrainé pour une tâche donnée, est utilisé comme point de départ d’un autre modèle à utiliser sur une seconde tâche.
Cette idée simple et efficace prend tout son sens lorsque l’Apprentissage des tâches à traiter prend énormément de temps. Pourquoi partir avec un modèle vierge, alors que l’on dispose potentiellement de modèles pré-entrainés pour des tâches plus ou moins similaire ?
Pour faire l’analogie avec l”être humain, notre système visuel extrait des caractéristiques (features), tels que des bords, des points saillants et des combinaisons de ceux ci. Nous avons appris à les extraire pour reconnaitre des visages. Il est tout à fait vraisemblable que lorsque nous reconnaissons des chiffres, nous utilisions ces mêmes caractéristiques.
L’idée du transfer learning est donc :
- d’utiliser les couches inférieurs d’un réseau de neurones pré-entrainé
- d’y ajouter un nouveau classifieur dédié à la nouvelle tâche à traiter
- d’entrainer le réseau complet sur une base de données correspondant à cette tâche. Pendant cet entrainement, seuls les poids des neurones de la seconde partie du réseau seront modifiées.
Cela peut fonctionner si les caractéristiques extraites par le premier réseau contiennent bien l’information pertinente pour la seconde tâche. Il n’y a pas vraiment moyen de s’en assurer (sauf par des tests).
Une idée générale peut néanmoins nous guider : dans un réseau de neurone, les caractéristiques extraites par les couches proches de l’entrée sont normalement les plus générales. Les couches proches de la sortie sont plus spécialisées pour le problème sur lequel elles ont été entrainées.
Il faudrait donc :
- Eliminer la derniere couche du réseau 1 (qui fait la classification)
- Eliminer aussi un certain nombre de couches du réseau 1 (qui seraient potentiellement trop spécialisées)
- Rajouter éventuellement quelques couches de spécialisation
- ajouter un nouveau classifieur en sortie.
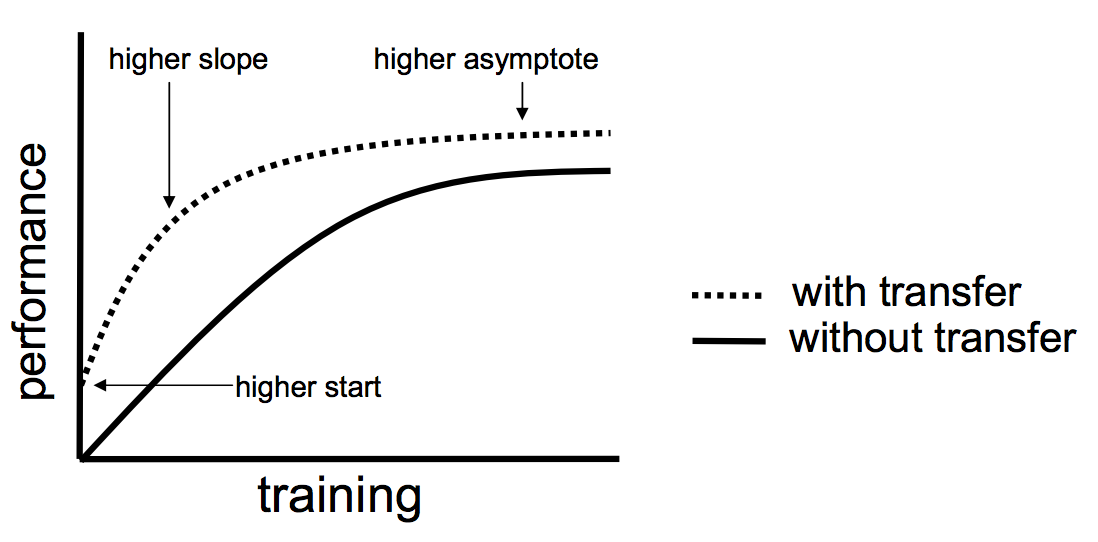
L’objectif du transfert learning est, finalement, d’améliorer les performances en apprentissage de plusieurs manières : (l’image vient d’ici )
Application
Une des bases les plus complètes d’images naturelles est la base ImageNet. elle sert de base pour une compétition de classification de photographies à 1000 classes (telles que “épagneul breton”, “setter irlandais”, “grand requin blanc” ou encore “papier toilette”). Elle contient plus d’un million d’images.
On peut récupérer des modèle de réseaux, pré-entrainés sur cette base. Dans le tutoriel que je vous propose ici (et qui vient directement de https://www.tensorflow.org/tutorials/images/transfer_learning ), nous souhaiterions utiliser un de ces modèles pour discriminer des chats et des chiens.
Si j’ai le temps, j’essaierais de l’utiliser dans une application visant à reconnaitre les chiffres de MNIST, par exemple.
Dans le cas de la reconnaissance des chats et des chiens, c’est à mon sens moins impressionnant, car le problème consiste a rassembler des classes existantes et éliminer les classes inutiles. Dans le cas de MNIST, ce serait intéressant de l’entrainer, puis de le tester avec des chiffres en couleurs…
Le tutoriel
Pour ce tutoriel, il vous faudra installer le module tensorflow_datasets dans votre environnement virtuel (au sujet des environnements virtuels, voir le cours sur les GAN ).
python -m pip install tensorflow_datasets