Performances
Dans ce chapitre, ce que je veux vous apprendre concerne tout d’abord les performances des algorithmes d’apprentissage automatique. Comment les mesure-t-on pour chaque type de problème (classification / régression / clustering) ? Nous verrons de plus que certaines mesures de performances peuvent apporter différentes informations utiles.
Nous verrons également dans la seconde partie de cet algorithme, la façon dont vos algorithmes d’optimisation peuvent trouver un bon jeu de paramètres pour votre modèle. Nous parlerons ainsi de l’adéquation nécessaire entre la complexité du problème et celle du modèle. Je vous décrirais enfin plus précisément le fonctionnement d’une descente de gradient, qui est la base de presque tous les algorithmes d’optimisation.
Commençons donc par voir comment mesurer les performances de nos algorithmes.
Mesures de performances d’un algorithme.
Nous savons déjà quelques petites choses sur ces mesures de performances.
En particulier, nous savons que :
-
dans le cas de l’apprentissage supervisé (classification ou régression), à la suite d’un apprentissage, on voudra évaluer les performances de l’algorithme sur une base d’exemples (base d’apprentissage ou base de validation).
-
dans le cas de l’apprentissage non supervisé (principalement le clustering), on voudra évaluer la qualité des clusters trouvés.
Jusqu’ici, nous n’avons évoqué comme mesure de performances que la probabilité de classification correcte, adaptée aux problèmes de classification. Il va être temps d’enrichir tout ceci.
Évaluations de performances pour la classification.
Proba d’erreur et proba de succès.
Nous l’avons déjà vu de nombreuses fois, la probabilité d’erreur est mesurée comme la proportion d’erreurs commises sur un ensemble d’exemples. Son pendant est la probabilité de classification correcte : la proportion de bonnes décisions.
Attention : Probabilité de classification correcte se traduit par « accuracy » en anglais Ceci est trompeur car la traduction littérale de « accuracy » est « précision », mais ce terme a, en français, un autre sens en apprentissage automatique, que l’on verra plus loin.
On pourra, par exemple, avoir un algorithme qui reconnaît les hommes et les femmes avec une accuracy de 0.9 en validation. On peut donc s’attendre à ce qu’il reconnaisse le sexe d’un individu dans 90% des cas en moyenne.
Mais ce n’est pas la seule façon d’évaluer les performances d’un algorithme de classification. Je vais vous en proposer quelques autres ci-dessous.
Matrice de confusion
L’objectif des matrices de confusion est d’en apprendre un peu plus sur les cas conduisant à des succès ou des échecs.
Considérons un exemple, dans un problème de classification à \(m\) classes. Pour un exemple, il y a \(m\) possibilités pour son label (sa vraie classe). Si je fais passer cet exemple dans un classifieur, il y a également \(m\) possibilités pour la classe prédite par l’algorithme. Les exemples se répartissent ainsi entre \(m \times m\) cas possibles, chacun correspondant à un couple \((vraie classe / classe prédite)\).
On compte, pour chaque classe possible \(y_i\) et chaque classe prédite possible \(ypred_j\), le nombre d’exemples d’une base correspondant au couple \((y_i, pred_j)\). Le nombre d’exemples obtenu est placé dans une matrice de taille \(m \times m\). La matrice ainsi construite s’appelle la « matrice de confusion » de l’algorithme. Elle comporte autant de lignes et autant de colonnes que de classes.
Voyons rapidement un exemple pour bien comprendre cette idée.
Prenons une base de 500 exemples (300 hommes et 200 femmes). Je noterais :
- label : le véritable sexe des individus, qui peut prendre les valeurs Homme, Femme, que je noterais ici respectivement \(Hvrai\) , \(Fvrai\)
- prediction : le sexe des individus prédit par l’algorithme, qui peut aussi prendre les valeurs Homme, Femme, que je noterais ici respectivement \(Hpred\), \(Fpred\).
On compte simplement pour chaque exemple dans quelle case \((label, prediction)\) il tombe.
Par exemple, on comptera le nombre d’exemples d’individus femme, dont l’algorithme a prédit qu’ils étaient des hommes. On placera ce nombre dans la case \((Fvrai, Hpred)\) de la matrice suivante.
On pourrait observer quelque chose comme :
| Hvrai | Fvrai | |
| Hpred | 280 | 10 |
| Fpred | 20 | 190 |
Les éléments sur la diagonale correspondent à des succès (la classe prédite et la vraie classe sont identiques). Toutes les autres cases correspondent à des erreurs.
Une matrice de confusion est souvent riche d’enseignements.
- On peut en déduire la probabilité de classification correcte de notre classifieur (ici (280 + 190) / 500 )
- On peut en déduire aussi la probabilité d’erreur de notre classifieur (ici (10 + 20) / 500 )
Notez que l’on souhaite parfois présenter cette matrice sous forme de probabilités. Si on divise le tout par le nombre d’exemples, cela estime la probabilité d’observer un sexe ET que l’algorithme fasse une prédiction donnée.
Voici par souci d’exhaustivité la matrice de confusion sous forme probabilisée, présentant \(P(label, prediction)\).
| Hvrai | Fvrai | |
| Hpred | 280 / 500 | 10 / 500 |
| Fpred | 20 / 500 | 190 / 500 |
Ce qui va suivre est peut être assez complexe à comprendre si vous n’avez pas eu de cours sur les variables aléatoires conjointes. Dans ce cas, pas de panique, nous reviendrons là-dessus grandement dans la section Théorie Bayésienne de la Décision du chapitre sur les Algorithmes.
Je vous présente aussi la version probabiliste présentant cette fois \(P(prediction / label)\). Prenez le temps d’observer le diviseur de ces probabilités - c’est le nombre d’exemples de la vraie classe correspondante (300 pour les hommes, 200 pour les femmes) .
| Hvrai | Fpred | |
| Hvrai | 280 / 300 | 10 / 200 |
| Fpred | 20 / 300 | 190 / 200 |
La matrice précédente me donne par exemple la probabilité que mon algo dise homme quand on lui présente une femme (10/100)
Cette dernière matrice me permet de voir que notre algorithme se débrouille moins bien pour reconnaître les hommes que pour reconnaître les femmes. Il commet des erreurs quand on lui présente un homme avec une probabilité de 0.066 (20/300), contre 0.05 pour les femmes (10/200)
C’est cette dernière matrice qu’il faut observer si l’on souhaite évaluer comment l’algorithme se débrouille sur les différentes classes du problème
Enfin, je peux aussi vous présenter la matrice suivante \(P(label / prédiction)\). Prenez le temps d’observer le diviseur de ces probabilités - c’est le nombre d’exemples de la classe prédite (290 pour les hommes, 210 pour les femmes) .
| Hvrai | Fpred | |
| Hvrai | 280 / 290 | 10 / 290 |
| Fpred | 20 / 210 | 190 / 210 |
La matrice précédente me donne entre autres la probabilité que l’exemple soit un homme quand l’algo dit femme (20/210)
Précision / Rappel
Les notions de précision et de rappel sont très importantes, car elles vous montreront que deux classifieurs présentant la même probabilité de classification correcte ne se valent pas forcément.
Ce sont des mesures que l’on utilise pour les problèmes à deux classes, en particulier dans le domaine des tests médicaux ou les problèmes de recherche de documents pertinents (moteurs de recherche). Il vous faudra sans doute plusieurs lectures pour réussir à comprendre les deux définitions qui suivent, et un peu de pratique pour les mémoriser .
La précision d’un algorithme est la proportion de vrais cas détectés parmi les détections que fait l’algo (en anglais, on l’appelle « precision ratio ou specificity »).
Le rappel d’un algorithme est la proportion de cas détectés parmi les cas qu’il aurait dû détecter. On l’appelle aussi sensibilité (en anglais, on l’appelle « recall ratio ou sensitivity »).
Pour bien comprendre ces notions, reprenons un exemple, correspondant à un test de grossesse (vous pouvez penser à un test du covid, si vous préférez)
Ci-dessous, je vous montre la matrice de confusion d’un algorithme donné, testé sur 800 femmes, dont 500 étaient enceintes, 300 ne l’étaient pas.
| Enceinte vrai | Pas enceinte vrai | |
| Enceinte pred | 480 | 10 |
| Pas enceinte pred | 20 | 290 |
La précision de cet algo compte les vraies détections (480) sur l’ensemble des détections faites par l’algo (490), soit 480/490 : 0.979
La précision est ici la probabilité d’être enceinte si le test dit que vous l’êtes.
Le rappel de cet algo, ou sa sensibilité, compte les vraies détections (480) sur l’ensemble des détections à faire (500), soit 480/500 : 0.96
La sensibilité (rappel) est ici la probabilité que le test dise que vous êtes enceinte si vous l’êtes.
Ces deux grandeurs sont importantes (on voudrait idéalement qu’elles soient toutes deux les plus grandes possibles).
Pour précisément l’importance de chacune, il va nous falloir encore un peu de vocabulaire :
- On appelle faux négatifs les cas attribués par erreur à un test négatif.
- On appelle faux positifs les cas attribués par erreur à un test positif.
Notez bien ce qui suit :
Si entre deux algorithmes, l’un présente une précision et une sensibilité meilleure que l’autre, c’est clairement le meilleur des deux. Si chaque algorithme a l’une des mesures en sa faveur, il faut choisir, en fonction de l’importance respective des Faux Positifs et des Faux Négatifs.
Je donne ci-dessous la matrice de confusion d’un autre algorithme, qui présente la même probabilité de classification correcte que le premier, mais dans lequel précision et rappel ne sont pas les mêmes :
| Enceinte vrai | Pas enceinte vrai | |
| Enceinte pred | 480 | 29 |
| Pas enceinte pred | 1 | 290 |
Ici, la précision vaut 480 / 509 (elle a baissé). Sa sensibilité est 480 / 481 (elle a augmenté).
Quel test préférez-vous ? Peut-être le premier (ca se discute), car avec le second, 29 femmes auront pensé être enceinte alors qu’elle ne l’étaient pas contre 10 pour le premier test. Cela représente beaucoup de fausses joies ou de grosses frayeurs. À l’inverse, 20 femmes enceintes pensent ne pas l’être avec le premier test. Elles le découvriront sans doute plus tard, sans que cela ait de grosses conséquences.
Ce qui est intéressant, c’est si l’on considère maintenant que ce test détecte les cancers en phase précoce, et non plus le fait d’être enceinte. Quel test préférez-vous ? Personnellement, je choisis sans hésiter le second. Au risque de me faire une grosse frayeur pour rien, je minimise les chances de passer à coté d’un diagnostic qui me sauverait peut-être la vie.
Imaginez maintenant une situation où le choix de la subvention d’un test ou d’un autre est une décision politique. Vous conviendrez sans doute qu’il vaut mieux que les différentes personnes en charge de ces problèmes, ainsi que les personnes en discutant dans la sphère publique soit, a minima, au point sur ces notions… (spoiler : pour les second, ce n’est pas toujours le cas).
Si vous êtes amenés à travailler sur un problème médical, vous croiserez à l’occasion d’autres notions du même ordre que celles que nous venons de voir. Pour ne pas alourdir inutilement ce cours, j’ai choisi de ne pas toutes les détailler. Avec ce que nous venons de voir, vous apprendrez à domestiquer leurs semblables par la pratique, si besoin est.
Voila qui clôt la présentation des quelques mesures de performances à retenir pour les problèmes de classification. Passons donc aux autres problèmes.
Mesures de performance pour la régression
Commençons par définir proprement notre problème de régression pour bien poser les notations.
On dispose d’exemples, définis par leurs vecteurs de caractéristique. Nous sommes dans un cadre d’apprentissage supervisé, donc à chaque exemple correspond une réponse attendue. Nous noterons cette réponse \(y\). On l’appelle souvent cible ou target dans les problèmes de régression. \(y\) est, dans le cas général, un vecteur de réels. Notre algorithme de régression devra, quand à lui, fournir sa réponse, sous forme d’un vecteur de même taille, que nous noterons \(yp\).
On pourra, par exemple, essayer de prédire la position finale d’une boule de billard, lancée sur un tapis donné, en fonction de la position initiale de la bille, de la direction donnée, des effets… Dans ce cas, la position finale est le couple de réels donnant la position de la bille sur le tapis. Le vecteur correspondant à une réponse est de dimension 2. Toutes les valeurs données seront supposées exprimées en centimètres.
La question centrale de cette section consiste à expliciter des mesures permettant de quantifier la qualité d’un algorithme de régression sur un ensemble d’exemples.
On commence par s’intéresser à l’erreur commise pour chaque exemple. Pour un exemple, cette erreur s’écrit \(e = y - yp\)
Si pour un exemple, la valeur attendue était \([0.4, 0.35]\) et que l’algorithme prédit \([0.5, 0.3]\). L’erreur commise est alors \([-0.1, 0.05]\). On voit que l’erreur est un vecteur de la taille de \(y\).
Dans le cas où le vecteur de sortie est de dimension supérieure à 1, notre mesure de performance devra combiner les erreurs commises sur chaque dimension.
De plus, il pour évaluer les performances sur l’ensemble de la base, il faudra aussi combiner les performances obtenues sur les différents exemples. Cette partie est la plus simple : si l’erreur sur un exemple est quantifiée, on mesure, en général, la performance moyenne sur l’ensemble des exemples.
Ci dessous, je vais vous présenter quelques exemples de mesure de performance sur un exemple donné.
Erreur quadratique et erreur quadratique moyenne
Une idée qui vous viendra peut être pour mesurer l’écart entre en un vecteur attendu et le vecteur en sortie du réseau est l’erreur quadratique existant entre ces deux vecteurs.
L’erreur quadratique est simplement la somme des carrés de l’erreur (on la nomme squared error en anglais, ou SE)
Compte tenu de nos notations, cela s’écrit :
Expression de la Squared Error : \(SE (y, yp) = \sum_i (y_i - yp_i)^2\)
Cette mesure est la base d’une des mesures de performances en régression couramment utilisées en apprentissage automatique :
L’Erreur Quadratique Moyenne ou Mean Squared Error (MSE): Si l’on souhaite mesurer la performance associée à N exemples, on calcule simplement la moyenne des erreurs quadratiques sur l’ensemble des exemples. On souhaite que cette MSE soit aussi faible que possible
Remarque : Notez que si l’on utilise l’erreur quadratique, on utilise le carré des écarts. Les grosses erreurs comptent beaucoup plus que les petites. Un écart de 0.8 sur une composante comptera pour 0.64 dans l’erreur quadratique. un écart de 0.1 comptera pour 0.01 (soit 64 fois moins que le précédent). Je reviendrais sur l’importance de cette notion dans les pages de niveau 2, lorsqu’on évoquera plus précisément l’importance des fonctions de coûts dans les algorithmes d’optimisation.
Une variante intéressante consiste à observer la racine carrée de la MSE calculée sur l’ensemble des exemples. On parle alors de Root Mean Squared Error. Vous la croiserez sans doute un jour ou l’autre aussi.
Erreur absolue et erreur absolue moyenne
Rien ne nous empêche d’utiliser une quantification différente de l’erreur. Par exemple, nous pourrions utiliser celle ci qui somme les valeurs absolues des écarts entre valeur attendue et valeur en sortie pour chaque exemple.
\[E (y, yp) = \sum_i |(y_i - yp_i|\]Comme précédemment, cette mesure d’erreur pour chaque exemple peut être moyennée sur un ensemble d’exemple.
l’Erreur absolue moyenne ou Mean Absolute Error (MAE) est la moyenne sur un ensemble d’exemples de la somme des valeurs absolues des compsante de l’erreur commise sur chaque exemple.
Si on utilise cette loss, on somme les valeurs absolues des écarts. Une grosse erreur compte proportionnellement autant qu’une petite. (un écart de 0.8 sur une composante comptera pour 0.8. Un écart de 0.1 comptera pour 0.1)
La Mean Absolute Error est souvent bien meilleure que la Mean Squared Error en termes d’interprétation des résultats.
Si l’on reprend notre exemple du billard, et que, sur l’ensemble de votre base de validation, vous obtenez une MAE de 1.5, cela signifie que pour chaque exemple en moyenne, vous vous trompez de 1.5, répartis sur les deux axes. Globalement, vous prédisez vos positions à 1.5 cm près.
Dans le cas de la MSE, mettons que vous obteniez 4.3. C’est la valeur moyenne de la somme des carré des composantes de l’erreur. Une façon de chiffrer grossièrement (et de facon inexacte) la précision de notre algorithme consiste à prendre la racine carrée de la MSE, qui nous indiquerait que nous prédisons nos valeurs à ~2.1 cm près en moyenne.
Conclusion
Avec tout ceci, nous disposons de deux mesures de performances pour la régression (MSE, MAE). Elles nous servirons à évaluer notre algorithme en fin d’apprentissage. Elles serviront également, pour l’algorithme d’optimisation, comme fonction de coût qu’il cherchera à minimiser pour définir les paramètres du modèle.
En termes d’interprétation, la MAE est souvent beaucoup plus parlante, mais gardez en tête l’existence des deux. Penchons nous maintenant sur le cas du clustering.
A noter : Si vos variables en sortie sont de nature très différente (disons que vous prédisiez une vitesse et un poids), rien ne vous empêche de mesurer la MAE sur chacune des sorties pour en faciliter l’interprétation.
Mesures de performance pour le clustering
Introduction et principe
L’objectif du clustering est de regrouper les points en groupes aussi homogènes que possibles, les groupes étant bien distincts entre eux. Ceci résume les deux propriétés des clusters que nous désirons trouver. On souhaite :
- des clusters présentant une forte séparation entre eux. La séparation sera indicative de la distance existant entre chaque cluster. Cette séparation serait, idéalement, aussi grande que possible.
- Des clusters présentant une grande homogénéité. L’homogénéité sera indicative de la compacité de chaque cluster. Plus le cluster est compact, mieux c’est.
Pour bien fixer les idées, je vais vous montrer quelques exemples de clusters, par ordre de qualité décroissante. Pour simplifier la visualisation, nous travaillerons dans un espace de dimension 2, mais gardez en tête que le problème général du clustering est traité en dimension quelconque.
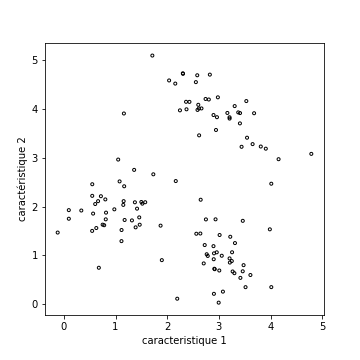
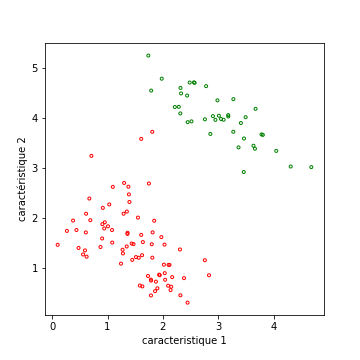
Tout d’abord, la figure suivante présente une situation facile, ou les clusters sont bien séparés (visuellement). Vous voyez peut être nettement 3 groupes de points.
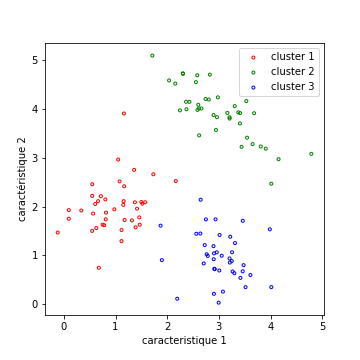
Ceci pourrait conduire au résultat de clustering suivant. Les groupes sont bien séparés, et les points d’un groupe bien compacts.
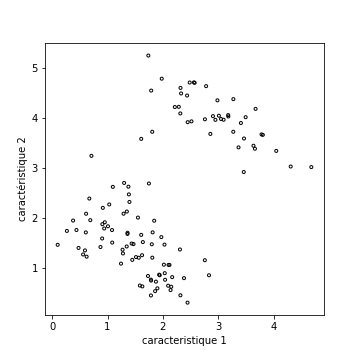
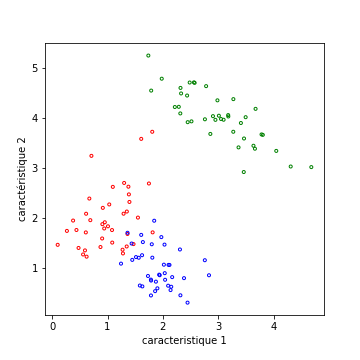
La figure suivante présente une situation plus complexe, et deux possibilités de clustering, soit en trois groupes, soit en deux :
| données | Résultat à 3 clusters | résultat à 2 clusters |
|---|---|---|
 |
 |
 |
Il est délicat, visuellement, de savoir s’il faut séparer en 2 ou en 3 groupes (en 3 groupes, les clusters rouges et bleus sont assez compact, mais peu séparés).
Enfin, on peut imaginer un algorithme qui, partant de la situation initiale précédente, donne les (très mauvais) résultats suivants :
| données | résultat à 2 clusters |
|---|---|
|
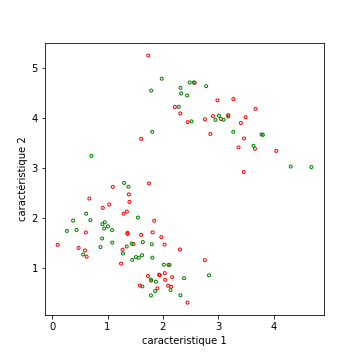 |
Dans ce dernier exemple, bien que la séparation soit relativement claire entre les deux groupes de points, l’algorithme les affecte de telle manière que les clusters ne sont ni homogènes, ni bien séparés.
L’objectif des mesures de performances pour le clustering est de quantifier la qualité des clusters trouvés, de façon à trouver les meilleurs groupes de points finaux. Nos mesures diraient ainsi que le dernier clustering est mauvais. Cette mesure peut aussi parfois être utilisée pour choisir le nombre de cluster optimal, permettant le choix entre 2 ou 3 clusters dans l’avant dernière figure.
Encore une fois, gardez en tête que, la plupart du temps, on travaille en dimension \(N > 3\), où l’on ne peut pas visualiser le problème dans son intégralité. Ces mesures de performances sont donc de précieuses informations sur la difficulté du problème et sur la qualité des clusters trouvés.
Tous les indices (les mesures de performances) présentés ci dessous utilisent les notions de séparation et d’homogénéité. Il diffèrent dans la façon dont elles sont calculées. Il est temps d’en décrire quelques unes.
Indice de Davies-Bouldin
Le problème de l’évaluation de la qualité des clusters rappellera peut être à ceux qui ont quelques connaissances en statistiques, des concepts associés à l’analyse de variance. Si l’on travaille sur une seule caractéristique, on peut ainsi s’intéresser à la variance intra-classe (les clusters sont ils bien homogènes ?) et à la variance inter-classe (les clusters sont ils bien séparés ?).
Ces idées peuvent être généralisées lorsque le nombre de dimensions augmente. Pour un problème de clustering à \(K\) clusters, On commence par calculer :
- le point moyen (barycentre) du nuage complet (tous clusters confondus). On le notera \(\mu\). Le nombre total de points est noté \(n\).
- le point moyen (barycentre) de chaque cluster \(C_k\). On notera ces barycentres \(\mu_k\). Le nombre de points dans chaque cluster est noté \(n_k\).
Pour représenter l’homogénéité d’un cluster, on calcule la moyenne des distances entre les points du cluster et son barycentre. C’est la variance intra-classe.
Calcul de la variance intra-classe dans un cluster \(C_k\) : \(W_k = \frac{1}{n_k} \sum_{p \in C_k} (\lVert p - \mu_k \rVert^2\)
La séparation existant entre deux classes données est içi simplement la distance \(\lVert \mu_k - \mu_{k'} \rVert^2\).
Ainsi, pour mesurer la qualité de 2 clusters, on peut regarder le ratio : \(\frac { W_k + W_{k'} } { \lVert \mu_k - \mu_{k'} \rVert^2}\). Plus ce ratio est faible, plus la séparation des clusters est bonne.
Avec ces quantités, on peut calculer l’indice de Davies-Bouldin, sur l’ensemble des clusters, par la formule suivante :
Davies-Bouldin : \(S_{DB} = \frac{1}{K} \sum_{k \in [1..K]} max_{k' \ne k} \frac { W_k + W_{k'} } { \lVert \mu_k - \mu_{k'} \rVert^2}\)
Retenons ces quelques règles :
- Plus ce clustering est bon, plus cet indice est proche de 0. Les variances intra-classes sont très faibles (numérateur), et les variances inter-classe fortes (faibles).
- Plus la qualité du clustering est mauvaise, plus cet indice est grand (les variances inter-classes tendant vers 0).
- il est délicat de l’utiliser pour choisir le nombre de cluster \(K\). Il convient bien, en revanche, pour choisir entre deux algorithmes pour un même problème, avec \(K\) fixé.
Indice de Calinski-Harabasz
Travaillant avec les mêmes notions, nous disposons également de l’ indice de Calinski Harabasz, plus proche des habitudes statistiques concernant la variance inter-classe.
Nous devons toujours calculer la variance intra-cluster de chaque cluster :
Calcul de la variance intra-cluster du cluster \(C_k\) : \(W_k = \frac{1}{n_k} \sum_{p \in C_k} (\lVert p - \mu_k \rVert^2 )\)
Par ailleurs, la variance inter-cluster, est représentative de la séparation des clusters.
La variance inter-cluster est la dispersion des barycentres autour du cluster moyen du nuage.
Formellement, elle se calcule comme suit :
Calcul de la variance inter-cluster : \(B = \sum_{i \in [1..K]} (n_k \times \lVert \mu_k - \mu \rVert^2 )\)
Avec ces quantités, on peut calculer l’indice de Calinski-harabasz, par la formule suivante :
Calinski-Harabasz : \(S_{CH} = \frac{(n-K) B}{(K-1) \sum_{i \in [1..K]} W_k}\)
Retenons ces quelques règles :
- Plus ce clustering est mauvais, plus cet indice est proche de 0. Les variances intra-classes sont très grandes, et la variance inter-classe faible.
- Plus la qualité du clustering est grande, plus cet indice est grand (les variances intra-classes tendant vers 0).
- il est délicat de l’utiliser pour choisir le nombre de cluster \(K\). Il convient bien, en revanche, pour choisir entre deux algorithmes pour un même problème, avec \(K\) fixé.
Indice de Silhouette
A titre personel, je préfère, aux deux précédents, utiliser l’ indice de Silhouette, qui n’utilise pas de calcul de barycentre. Or les barycentre n’ont parfois aucun sens pour certains problèmes.
L’indice de silhouette calcule, pour chaque point \(i\), deux grandeurs :
-
\(a(i)\) la distance moyenne du point aux points de son cluster. Elle est représentative de la facon dont un point est bien inséré dans son cluster, donc de la compacité du cluster.
-
\(b(i)\) le minimum des distances moyenne du points aux points des autres clusters. Elle est représentative de la séparation existant entre ce cluster et les autres.
L’indice de silhouette d’un point \(i\) est alors donné par : \(sil(i) = \frac{ b(i) - a(i)}{max (b(i), a(i))}\)
Quelques remarques sur cet indice :
- La division par le max de (a(i)) et (b(i)) sert simplement à ramener la valeur de silhouette dans l’intervalle [-1, 1].
- Un point plus proche des points de son groupe que des points d’un autre cluster aura un indice de silhouette positif.
- Un point plus proche des points d’un autre cluster que des points de son cluster aura un indice de silhouette négatif.
- Un point à égale distance de deux clusters aura un indice de silhouette nul.
On peut alors utiliser cet indice calculé pour chaque point, pour définir la qualité d’un cluster en particulier.
L’indice de silhouette d’un cluster est la moyenne des indices de silhouette de chacun de ses points.
Enfin, on peut mesurer la qualité de l’ensemble des clusters, qui constitue une évaluation des résultats de notre algorithme
L’indice de silhouette d’un algorithme de clustering est la moyenne des indices de silhouette de chacun des cluster qu’il a défini.
Ci dessous, je vous présente certaines des différentes situations présentées précédemment, et les valeurs de silhouette correspondantes :
| clusters | |
|
|
| Indices de silhouette | -0.047 | 0.638 | 0.498 |
Enfin, sachez qu’il est possible de visualiser à la fois les indices de silhouette de chaque point et ceux de chaque cluster. Je vous le représente dans la figure suivante. A gauche, les valeurs des indices de silhouette pour chaque point, rangées par ordre décroissant dans chaque cluster. A droite, les données et les clusters obtenus par l’algorithme, représentés par les mêmes couleurs qu’a gauche. On le voit, les clusters numérotés 0 et 2 contiennent des points dont l’indice de silhouette est négatif (ce sont les points à la frontiere entre cluster 0 et cluster 2)
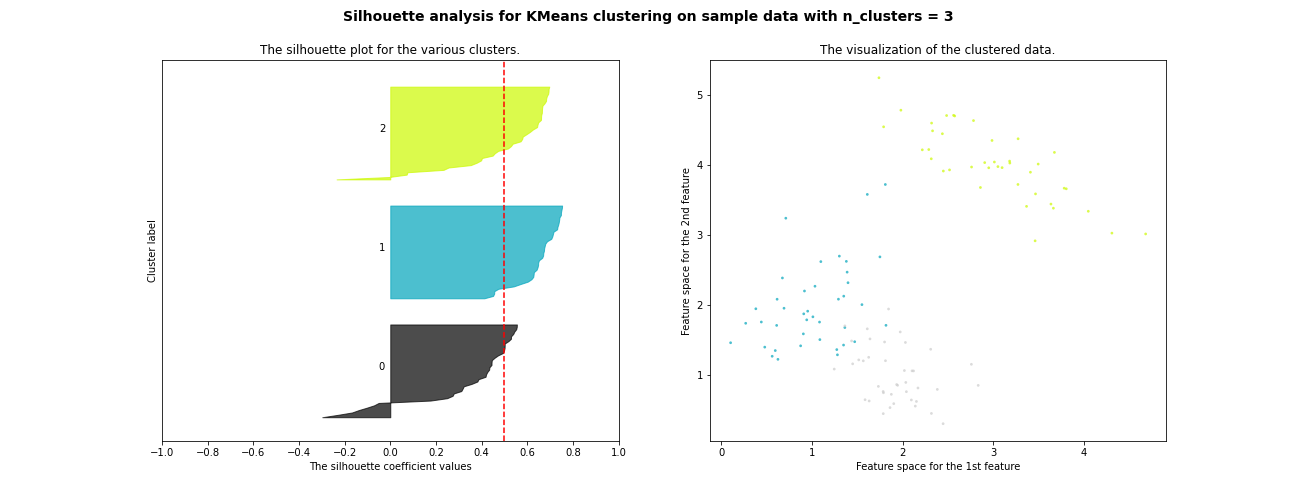
Conclusion sur les mesures de performances pour le clustering
A ce stade, nous disposons de 3 mesures qui pourront être utilisées pour quantifier la qualité des clusters trouvés par un algorithme. Il en existe de nombreuses autres, et pour celles que nous avons vues, de nombreuses variantes.
Celles que nous venons de voir nous suffiront amplement pour avoir de solides bases sur ce point.