Bases d’exemples
Séparer sa base d’exemples
Pour les applications d’apprentissage supervisé, il arrive fréquemment qu’on dispose d’une unique base d’exemples (la base initiale), définis par leur caractéristiques et munis d’une vérité associée. À partir de ces exemples, nous avons déjà vu qu’il nous faudrait créer au moins 2 bases :
- la base d’apprentissage,
- la base de validation (appelée aussi base de généralisation. je mixerais souvent ces termes).
Il faut aussi définir combien d’exemples feront partie de chaque base.
De façon générale, on mettra quasiment toujours plus d’exemples dans la base d’apprentissage que dans la base de validation. Il faut en effet une base d’apprentissage aussi grande que possible pour que l’algorithme puisse extraire des règles de décisions les plus fines possibles. La taille de la base de validation doit être limitée à un minimum permettant de faire une évaluation correcte des performances. La base de généralisation doit néanmoins une taille suffisante pour fournir une variété de cas représentative des cas réels.
Règle ad hoc pour les tailles de base.
Cette règle est complètement empirique et concerne la taille relative des 2 bases. Les valeurs de proportion et de taille limite des bases sont purement indicatives.
Petites bases
Pour une base de moins de 1000 exemples, on pourrait choisir quelque chose comme :
- 66% (2/3) des exemples iront en apprentissage
- 33% (1/3) iront en validation
Grandes bases
Pour une base de plus de 100 000 exemples, on pourrait prendre quelque chose comme :
- 90% (9/10) apprentissage
- 10% (1/10) validation
Entre ces deux cas, on pourra utiliser des proportions intermédiaires (3/4 ou 4/5)
Voyons maintenant comment opérer cette séparation.
Algo de séparation des bases.
Les deux bases doivent avoir des propriétés statistiques semblables même si c’est délicat à expliquer. Par exemple, on ne voudrait pas :
- Qu’une base contienne bcp d’exemples d’une classe alors que l’autre n’en contiendrait que peu ;
- Qu’une base contienne tous les exemples faciles, alors que l’autre contiendrait tous les exemples difficiles.
Principe de base
Si l’on dispose de suffisamment d’exemples, et que les classes sont équilibrées, on peut sans problème procéder comme suit :
- On fixe une proba p d’appartenir à la base d’apprentissage (p=0.66 par exemple)
-
Pour chaque exemple :
- on tire un nombre tirage aléatoirement entre 0 et 1.
- Si tirage < p, on range l’exemple dans la base d’apprentissage.
- Sinon, on range l’exemple dans la base de généralisation.
Ceci garantit que les bases soient à peu près bien formées.
Comme nous l’avons vu dans les Applications Pratiques des pages de base, en Python, la fonction train_test_split du module sklearn.model_selection permet d’effectuer cette opération très simplement.
Principe amélioré
Il peut être important, si certaines classes sont peu représentées, de bien veiller à ce que certaines classes ne disparaissent pas ou presque de l’une ou l’autre des bases. On prendra alors certaines précautions lors des tirages aléatoires pour que ceci ne se produise pas.
Par exemple, on pourrait au préalable :
- Séparer la base initiale selon les classes des exemples ;
- Compter le nombre d’exemples total et le nombre d’exemples de chaque classe de la base initiale ;
- Utiliser p pour établir le nombre d’exemples attendu pour chaque classe, dans chaque base ;
- Pour chaque classe, on pourra alors choisir aléatoirement dans la base initiale le bon nombre d’exemples d’une classe à affecter à la base d’apprentissage. Les autres iront dans la base de validation.
En Python, la fonction train_test_split du module sklearn.model_selection permet de choisir ce comportement avancé, avec le paramètre stratify.
Les types de caractéristiques
Ici, on s’intéressera aux différents types de caractéristiques possibles pouvant permettre de composer les vecteurs de caractéristiques. La typologie qui suit vient des proba/stat mais nous l’adopterons au vu des liens qui existent entre cette discipline et l’apprentissage automatique.
On distingue essentiellement deux grandes catégories : les variables quantitatives et les variables qualitatives.
Variables quantitatives
Les variables quantitatives sont des informations qui prennent la forme de nombres.
Par exemple, concernant un individu, on peut penser à son nombre d’enfants, sa taille, son âge…
En ce qui nous concerne, c’est parfait, ces nombres peuvent être directement injectés dans un classifieur. Pour le probabiliste, il convient néanmoins de distinguer deux cas : les variables discrètes et les variables continues car les techniques employées pour les traiter diffèrent. Pour nous, le plus souvent, cela ne change pas grand chose.
Les variables quantitatives discrètes
On parle de variable discrète lorsque les valeurs possibles sont entières (ou représentent un ensemble discret, comme \({1.2, 4.3, 4.6, 5.2}\))
Par exemple, le nombre d’enfants d’un individu. On a rarement 1.3 enfant.
Les variables quantitatives continues
On parle de variable continue lorsque les valeurs possibles sont réelles.
Par exemple, la taille d’un individu est plutôt une variable continue. L’âge d’un individu est moins clair. C’est théoriquement un nombre réel, mais on ne le définit au mieux qu’au jour près, et le plus souvent, on le donne sous forme d’entier.
Variables qualitatives
Les variables qualitatives sont des informations qui ne prennent pas la forme de nombres. Elles représentent en général les modalités d’une caractéristique (les catégories possibles d’une caractéristique).
Pour mieux comprendre cette notion, on pourra citer comme exemples la couleur des yeux d’un individu (vert, bleus, marrons,…), ou la taille d’une société (TPE, PME, GE).
Il peut arriver que ces données arrivent sous forme d’une chaîne de caractères, qui ne peut pas être injectée telle quelle dans les classifieurs. Il va donc être nécessaire de les pré-traiter. Le prétraitement peut différer en fonction de la sous catégorie de variable, selon qu’elle est ordinale ou nominale.
Variables qualitatives ordinales
On parle de variable qualitative ordinale lorsque les modalités possibles possèdent la propriété d’ordre (qu’ont peut les classer par ordre croissant ou décroissant).
Par exemple, la taille d’une entreprise est clairement ordonnée.
Dans ce cas, on peut éventuellement encoder ces informations sous forme d’un entier comme indiqué dans le tableau suivant. |:—:|:—:|:—:|:—:| | Taille de l’entreprise | TPE | PME | GE | | Encodage | 0 | 1 | 2 |
Il arrive couramment que les bases d’exemples dont on dispose encodent déjà leurs caractéristiques quantitatives avec ce format.
Notez qu’on aurait pu aussi encoder/changer l’échelle de l’encodage pour qu’elle contienne l’information du nombre minimal d’employés dans chaque structure, ce qui donnerait ce qui suit :
| Taille de l’entreprise | TPE | PME | GE |
| Encodage | 1 | 10 | 250 |
Ceci peut être important si la décision de notre algorithme peut bénéficier d’un peu de finesse concernant cette information.
Variables qualitatives nominales
On parle de variable qualitative nominale lorsque les modalités possibles ne possèdent pas la propriété d’ordre (qu’on ne peut pas les classer par ordre croissant ou décroissant).
C’est le cas de la couleur des yeux par exemple.
Ce cas des variables qualitatives nominales est assez important pour nous. On pourrait imaginer reprendre l’encodage vu ci-dessus, qui donnerait donc, par exemple :
| Couleur des yeux | vert | marron | bleu |
| Encodage | 0 | 1 | 2 |
Ce sera même parfois le cas dans les bases que vous aurez à utiliser.
Important : Néanmoins, cet encodage peut parfois rendre la tâche de nos algorithmes beaucoup plus compliquée.
En effet, un algorithme de classification manipule des chiffres, des distances, des moyennes. Or dans l’absolu, bleu n’est pas deux fois plus que marron, …
Vous pouvez toujours essayer cet encodage basique. Après tout, si les performances sont satisfaisantes, pourquoi chercher mieux ?
Il est éventuellement préférable d’encoder ces caractéristiques en utilisant la notion de One Hot Vector.
Dans l’encodage One Hot Vector, la caractéristique est remplacée par un vecteur dont la taille correspond au nombre de modalités possibles. Chaque modalité possible est encodée par un vecteur ne comprenant qu’un seul 1.
Par exemple :
| Couleur des yeux | vert | marron | bleu |
| Encodage | (1,0,0) | (0,1,0) | (0,0,1) |
Ainsi, un algorithme distingue aisément que ces catégories sont très différentes.
Conclusion sur les types de caractéristiques
De fait, cette typologie n’est pas à apprendre par cœur, pour nous. On conservera surtout en tête la différence entre variables quantitatives et qualitatives.
Les variables qualitatives doivent être encodées numériquement. On pourra éventuellement s’intéresser à la pertinence d’un encodage One Hot Vector pour certaines caractéristiques qualitatives, si les performances de nos algorithmes restaient décevantes malgré tous nos efforts.
Normalisation des caractéristiques
Ce point a été abordé très brièvement au cours de l’application pratique 1.2. Je vais ici le détailler un peu plus précisément.
Les algorithmes d’apprentissages automatiques manipulent des caractéristiques numériques, sur lesquelles ils font des calculs très divers qui mélangent allègrement ces caractéristiques.
Important : Il est primordial pour de nombreux algorithmes que, d’un exemple à l’autre, chaque caractéristique fluctue avec le même ordre de grandeur. Il est aussi important que la valeur moyenne des caractéristiques soit relativement semblable.
Imaginez que l’on s’intéresse au poids (en kg) et à la taille (en mètres) de différents individus. La taille moyenne est de l’ordre de 1.7, le poids moyen est de l’ordre de 65kg. Par ailleurs, une fluctuation de taille typique entre deux individus sera de l’ordre de 0.1 (10 cm), alors que la fluctuation typique de poids serait plutôt de 10 (10kg). Dans cet exemple, nos deux caractéristiques occupent des portions de \(\mathbb{R}\) très différentes.
Ce type de situation met en difficulté un grand nombre d’algorithmes, pour des raisons variées.
Pour remédier à cela, il sera utile de procéder à la normalisation de chaque caractéristique, qui va toutes les ramener dans des portions de \(\mathbb{R}\) semblables.
Il existe de multiples façons d’opérer cette normalisation. Je vais ci-dessous en décrire quelques unes.
Chacune de ces techniques est implémentée en Python par le module preprocessing de la librairie Scikit Learn.
Normalisation standard
La technique de normalisation standard, appelée aussi « standardisation », consiste à retirer sa moyenne à chaque caractéristique, puis à diviser le résultat par l’écart type.
C’est ce que j’avais fait dans l’application pratique 1.2.
Dans la pratique, on mesure, pour chaque caractéristique, sa moyenne \(m\) et son écart type \(\sigma\) sur l’ensemble de la base d’apprentissage (ou sur l’ensemble des exemples pour du clustering).
Puis, pour chaque exemple, on calcule la nouvelle caractéristique \(x_{norm}\), calculée à partir de la caractéristique d’origine \(x\) avec la formule suivante :
Formule de standardisation : \(x_{norm} = \frac{x-m}{\sigma}\)
À l’issue de ce traitement, \(x_{norm}\) a une moyenne nulle et un écart type de 1.
Dans le cas d’applications d’apprentissage supervisé, il faudrait procéder comme suit :
- On mesure \(m\) et \(\sigma\) pour chaque caractéristique, sur la base d’apprentissage.
- On applique la formule pour chaque caractéristique et chaque exemple de la base d’apprentissage.
- On applique la formule pour chaque caractéristique et chaque exemple de la base de validation, en utilisant les valeurs mesurées en 1.
- Si l’on souhaite faire une prédiction sur un exemple quelconque, hors des bases, il faudra également lui appliquer la standardisation, toujours en utilisant les valeurs mesurées en 1.
Il faut noter que l’on ne garantit pas l’intervalle de valeurs dans lequel évolue \(x_{norm}\).
En python, c’est un objet StandardScaler qui est en charge de ceci.
Normalisation
La normalisation à proprement parler consiste à ramener chaque caractéristique dans l’intervalle \([0,1]\).
Pour cela, on calcule, le minimum et le maximum de chaque caractéristique sur l’ensemble des exemples de la base d’apprentissage (ou sur l’ensemble des exemples pour du clustering), puis on applique la formule suivante :
Formule de normalisation : \(x_{norm} = \frac{x-min}{max - min}\)
Dans le cas d’applications d’apprentissage supervisé, il faudrait procéder comme suit :
- On mesure \(min\) et \(max\) pour chaque caractéristique, sur la base d’apprentissage.
- On applique la formule pour chaque caractéristique et chaque exemple de la base d’apprentissage.
- On applique la formule pour chaque caractéristique et chaque exemple de la base de validation, en utilisant les valeurs mesurées en 1.
- Si l’on souhaite faire une prédiction sur un exemple quelconque, hors des bases, il faudra également lui appliquer la normalisation, toujours en utilisant les valeurs mesurées en 1.
Il faut noter qu’il est possible que certains exemples hors de la base d’apprentissage aient des caractéristiques hors de \([0,1]\) (si l’une de leur caractéristiques est hors des intervalles \([min, max]\) mesurées sur la base d’apprentissage. En général, cela ne posera pas vraiment de problème.
En python, c’est un objet MinMaxScaler qui est en charge de ceci.
Normalisation de données séquentielles
Dans le cas de données correspondant à une séquence, comme une séquence temporelle dans le cas d’un signal sonore, ou une séquence spatiale dans le cas d’images, il ne faut pas normaliser ses données comme on l’a vu précédemment.
Prenons un exemple, dans lequel nos données seraient des images. Cela n’aurait pas de sens, sur l’ensemble des images de la base, de normaliser chaque premier pixel des images, puis chaque second, etc… Cela romprait la cohérence de chaque image.
Dans ces cas là, si l’on souhaite que les séquences soient normalisées, on peut (au choix):
- mesurer l’écart type et la variance de chaque séquence et standardiser la séquence avec la formule de standardisation ;
- mesurer le min et le max de chaque séquence et normaliser la séquence avec la formule de normalisation ;
- on peut également, dans le cas d’images, simplement diviser la valeur de chaque canal RGB par 256 pour la ramener entre 0 et 1.
Conclusion
Je ne vais pas illustrer l’intérêt de ces techniques, nous en avons déjà eu un aperçu dans les applications pratiques. J’insiste néanmoins sur le point suivant :
Si vos algorithmes ne fonctionnent pas très bien, l’un des premiers points à vérifier, c’est que vous avez appliqué une technique de normalisation adaptée à vos données !
La malédiction de la dimensionalité
Le principe
Ce problème concerne les applications de classification de régression et de clustering. Je vais l’illustrer pour un problème de classification.
Quel que soit le problème que vous vouliez traiter, il semble intéressant de disposer d’autant d’informations que possible à propos des objets que vous voulez classifier.
Par exemple, on peut se dire qu’un algorithme devant déduire le sexe d’un individu, qui travaille sur un vecteur de caractéristiques \([taille, poids]\) sera moins efficace qu’un algorithme travaillant sur les caractéristiques \([taille, poids, longueurCheveux, salaire, prixVoiture,...]\)
Étonnamment, avoir plus d’informations sur chaque exemple peut parfois conduire à un algorithme moins efficace.
La raison pour laquelle ceci peut se produire est la suivante : Quel que soit l’algorithme que vous utilisiez, il s’appuiera sur les exemples que vous lui fournirez pour prendre sa décision. Le nombre d’exemples d’apprentissage est donc directement lié à la connaissance que votre algorithme aura du problème à traiter. Or la taille du vecteur de caractéristiques influe grandement sur le nombre d’exemples dont on doit disposer pour que l’algorithme dispose de suffisamment d’informations.
Ce que je vais montrer ci-dessous, c’est que pour un nombre d’exemples donnés, il va y avoir un compromis à trouver :
- peu de caractéristiques => problème mal connu (c’est évident),
- trop de caractéristiques => pas assez d’exemples pour bien connaître le problème.
Vous pouvez sauter la section suivante si vous avez du mal avec les calculs, je vais essayer de quantifier ceci grossièrement.
Quantifions ceci
Je vais prendre un exemple simple pour vous donner une idée de la démonstration de ce point. Disons que :
- chacune de nos caractéristiques est discrète et prend une valeur entre 0 et 9 (il y a 10 valeurs possibles par caractéristique) ;
- on dispose au total de N exemples.
Intuitivement, on peut se douter que la connaissance de notre problème est liée au nombre d’exemples pour chaque valeur possible des caractéristiques. En effet, imaginons par exemple que dans notre base d’exemple, une valeur de caractéristique apparaisse peu pour une classe, et à peine plus pour une autre. Avec un nombre d’exemples élevé pour cette valeur des caractéristiques, on pourra conclure avec confiance que même si ces classes sont peu représentées, la seconde classe est effectivement plus probable. Avec un nombre d’exemples faible, un fort doute subsiste et la différence entre les deux est peut être simplement due à notre sélection d’exemples.
S’il n’est pas possible d’évaluer ce nombre d’exemple pour chaque valeur possible, on peut en revanche calculer le nombre moyen d’exemples pour chaque valeur possible des caractéristiques, qui nous donnera une indication précieuse sur l’évolution générale de nos connaissances d’un problème. Calculons donc ce nombre moyen, lorsque le nombre de caractéristiques \(d\) varie.
d=1 (une seule caractéristique)
Tous mes exemples tombent dans l’une des 10 valeurs possibles pour cette caractéristique. Le nombre moyen d’exemples par valeur possible est donc \(m_1 = N /10\)
d=2 : (deux caractéristiques)
Chaque exemple possible est caractérisé par un couple de valeur. Il y a donc \(10^2\) valeurs possibles pour mes vecteurs de caractéristiques. Le nombre moyen d’exemples par valeur possible est donc \(m_2 = N /10^2\)
d quelconque (cas général)
On montre relativement facilement que le nombre moyen d’exemples par valeur possible est \(m_d = N /10^d\)
Les implications
Comme on le voit, le nombre moyen d’exemples par valeur possible décroît exponentiellement par rapport au nombre de dimensions.
En augmentant le nombre de caractéristiques, l’information que je tire d’un exemple décroît de façon exponentielle.
Voyons le problème de l’autre côté. Disons que l’on veut garantir un nombre moyen d’exemples par valeur possible constant.
Disons que 100 exemples sont suffisants pour classifier selon le poids seulement. Ce nombre moyen utile est \(m_1 = 100/10 = 10\)
On veut ajouter une information (la taille). Il nous donc faudra ajouter des exemples pour conserver ce nombre moyen d’exemples. On veut donc \(m_2 >= m_1\).
Ce qui implique : \(N/10^2 >= m_1\) soit \(N >= m_1 * 10^2\).
Quand on augmente encore, pour un problème à d caractéristiques, on a \(N >= m_1 * 10^d\).
Si l’on chiffre ceci, il faudrait :
- d = 2 : \(N = 10*10^2 = 1000\) exemples pour la \([taille, poids]\).
- d = 3 : \(N = 10*10^3 = 10000\) exemples pour \([taille, poids, longueurCheveux]\)
- d = 5 : \(N = 10*10^5 = 1 000 000\) exemples pour \([taille, poids, longueurCheveux, salaire, prixVoiture,...]\)
Conclusion
La malédiction de la dimensionalité (the curse of dimensionality) *le terme vient de Richard E. Bellman en 1957** est une propriété qui veut que le nombre d’exemples nécessaires pour traiter un problème d’apprentissage supervisé augmente de façon exponentielle avec le nombre de caractéristiques.
On voit ainsi qu’il serait important de conserver uniquement des informations pertinentes pour la classification, sinon le nombre d’exemples nécessaires peut devenir rapidement ingérable.
En résumé, si votre algorithme a de mauvaises performances, peut être est ce que :
- le problème est intrinsèquement trop difficile (par exemple, prédire le QI d’un individu à partir de son sexe et de sa taille semble très délicat) ;
- votre algorithme est mauvais (le modèle est trop simple ou l’algorithme d’optimisation ne converge pas bien) ;
- votre algo n’a pas assez d’informations (de caractéristiques) ;
- votre algo doit traiter trop d’informations (de caractéristiques) pour la base d’exemples que vous lui avez fourni.
Ce dernier point était l’objet de la présente section !
Sélection manuelle des caractéristiques
Comme signalé dans la partie portant sur la malédiction de la dimensionnalité, il est parfois nécessaire de limiter le nombre de caractéristiques. Nous verrons dans les pages de niveau 2 une méthode (l’Analyse en Composante Principale) permettant éventuellement de réduire ce nombre de caractéristiques, mais dans cette section, nous nous concentrerons sur la sélection manuelle par simple inspection visuelle.
Cela me permettra aussi de revenir sur l’importance de visualiser ses données, ce qui est forcément délicat lorsque l’on travaille dans des espaces vectoriels de dimensions supérieures à 3.
Dans ce qui suit, j’ai utilisé la base d’exemples Heart Disease Cleveland, que vous avez déjà croisée dans Applications Pratiques 1.
Visualisation d’une seule caractéristique
Imaginons que l’on veuille observer la répartition d’une caractéristique des exemples dont on dispose. Nous allons voir différentes façons de visualiser ces informations.
Nuage de Points
Le plus simple est de regarder le nuage de points 1d de cette caractéristique. En ordonnée, une constante, en abscisse, le cholestérol. Chaque point est un patient.
Il pourrait être intéressant de visualiser notre caractéristique pour chacune des classes possibles.
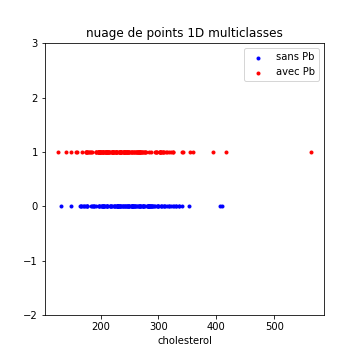
Ici, par exemple, on ne trouve pas à première vue de différence flagrante entre les deux classes…
Histogrammes
Pour obtenir plus d’informations sur la distribution de cette caractéristique, on peut tracer l’histogramme d’une caractéristique.
Dans la figure qui suit, j’ai tracé l’histogramme du cholestérol des personnes sans problème cardiaque, ainsi que celui des personnes ayant des problèmes cardiaques. L’ordonnée est normalisée pour être homogène à une densité de probabilité.
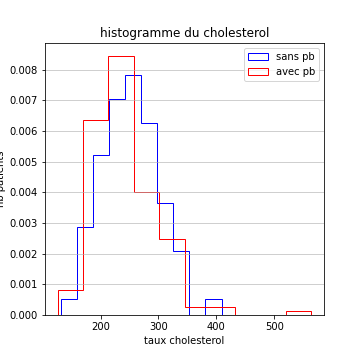
C’est confirmé, les distributions sont très semblables (des gaussiennes ou presque, de moyenne et variance très similaires).
On peut faire ceci pour toutes les caractéristiques. Pour des raisons pratiques, je présente ci-dessous les histogrammes de toutes les caractéristiques pour les patients sans problème cardiaque, avant de faire de même pour les patients avec problèmes cardiaques.
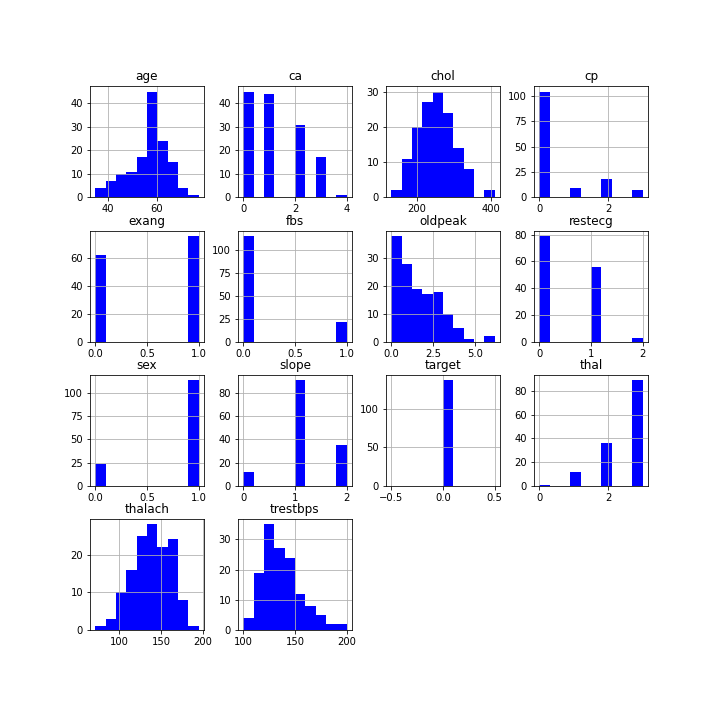
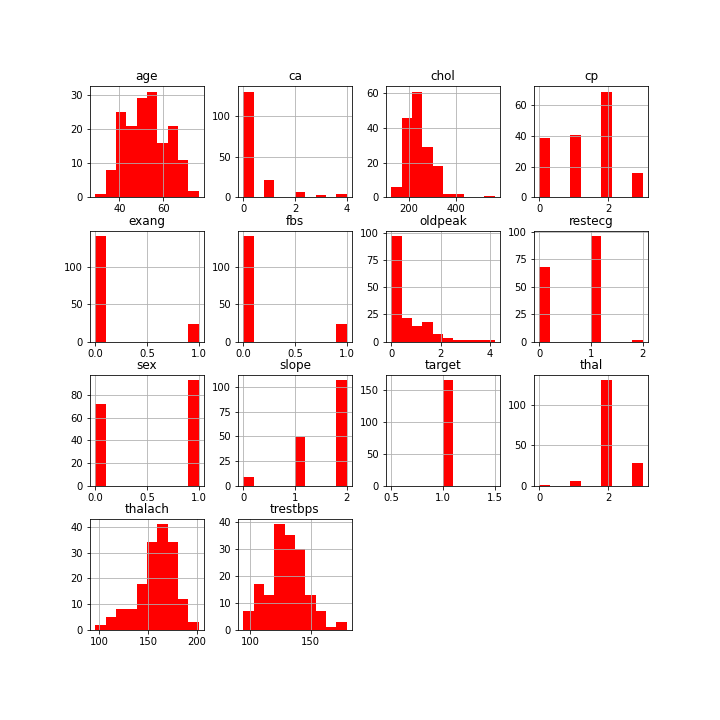
On va chercher dans ces courbes des caractéristiques dans lesquelles les histogrammes des différentes classes se superposent le moins possible.
Ceci permet par exemple de se rendre compte que talach et thal semblent être intéressants pour détecter partiellement les problèmes cardiaques (j’ai regardé vraiment rapidement).
Visualisation de deux caractéristiques
Si on ne regarde les caractéristiques que l’une après l’autre, on peut passer à côté d’informations primordiales, concernant les liens statistiques entre les caractéristiques. Voici ci-dessous le nuage 2D age / talach, pour l’ensemble des patients.
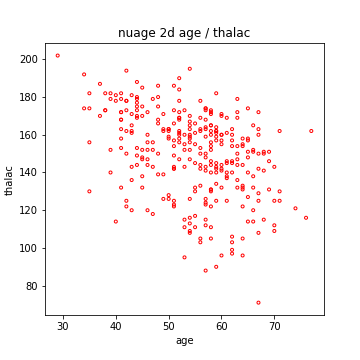
On voit clairement que la seconde caractéristique (thalach) diminue en moyenne lorsque l’âge augmente.
Par ailleurs, et pour revenir à la sélection des données, si j’observe les caractéristiques pour chaque classe, cela peut être très intéressant :
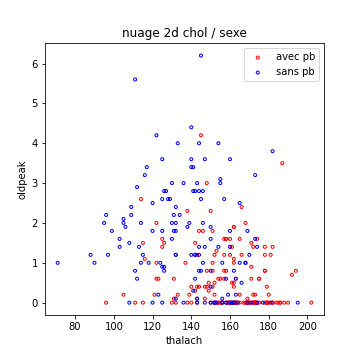
Le graphe précédent montre clairement que le couple thalach / oldpeak permet de discriminer pas mal les patients atteints de problèmes cardiaques et les autres. Ceci serait très utile si, par exemple, je ne devais conserver que quelques caractéristiques pour réduire la dimension du problème.
Visualisation de trois caractéristiques
Je vous mets ci-dessous un nuage 3D. C’est beau et parfois utile, mais surtout si on peut le faire tourner pour l’observer sous plusieurs angles…
Dans le cas du graphe précédent, si on ne peut pas le faire tourner, il est difficile d’en tirer des conclusions.
Voilà, donc ce qui clôt notre bref aperçu de ce que l’on peut faire en visualisation de données, notamment pour choisir les caractéristiques les plus pertinentes.
Par ailleurs, comme je crois fermement aux vertus du copier-coller dans l’apprentissage de l’informatique, vous trouverez ici un lien vers le Jupyter Notebook ayant permis de créer ces courbes : https://colab.research.google.com/drive/1hUqTKF5Zh_gfj79aelprjQz1Y_lq37KK?usp=sharing