Formalisation
Rappelons tout d’abord notre objectif. Pour mieux l’expliquer, je vais reprendre l’exemple de classification vu dans la section précédente : Ce que nous cherchons à mettre au point n’est pas un programme qui reconnaisse au mieux les hommes et les femmes sur la base de leur poids et de leur taille, mais un programme qui, si on lui donne des exemples de (taille, poids, sexe) sera capable de choisir un sexe pour n’importe quelles entrées (taille, poids).
Il s’agit donc de se détacher du problème précis, pour trouver des solutions plus ou moins universelles à ces problèmes généraux. Mais comme nous devons discuter de ces problèmes, il nous faut un peu de vocabulaire.
Le vecteur de caractéristiques
Tout d’abord, nous l’avons vu, nous étudions des objet ou des situations, chacune définie par un ensemble de caractéristiques (ou features).
Important : Ces caractéristiques devront être présentés à nos algorithmes sous forme de nombres (ce qui pourra parfois nécessiter un léger prétraitement. Imaginez qu’une de vos caractéristiques soit la couleur des yeux. Il faudra l’encoder sous forme de nombres. Nous aurons plusieurs solutions pour cela).
Ces nombres sont rangés dans un vecteur, que l’on nomme « vecteur de caractéristiques » (ou encore feature vector en anglais).
- Dans les applications de clustering et de classification que nous avons vues, notre vecteur de caractéristiques était le vecteur [taille, poids].
- Dans le cas de la régression présentée précédemment, les informations dont nous disposions étaient une seule valeur nbClopes que l’on peut voir comme un vecteur de dimension 1 [nbClopes].
La taille de ce vecteur est extrêmement importante. Cette taille est appelée « dimension de l’espace des caractéristiques ». C’est de cet espace dont nous allons parler maintenant.
L’espace des caractéristiques
Définition : Le vecteur constitué des caractéristiques de chaque exemple appartient à un espace vectoriel : l’espace des caractéristiques. C’est l’ensemble de positions possibles pour nos exemples.
Notre espace des caractéristiques est (inclus dans) :
- \(\mathbb{R}^2\) lorsque le vecteur de caractéristiques est [tailles, poids] ;
- \(\mathbb{R}\) lorsque le vecteur de caractéristiques est [nbClopes].
La taille de l’espace des caractéristiques est primordial en Apprentissage Automatique. En particulier, du fait de la Malédiction de la dimensionalité, que nous verrons plus loin, plus ce vecteur sera grand, plus il faudra d’exemples pour apprendre.
Notez que nous travaillerons couramment avec des espaces de caractéristiques de dimensions 3,4, 100 ou 1000. Une branche complète de l’apprentissage automatique s’intéresse aux espaces de grandes dimensions, c’est ce que l’on a nommé un certain temps « Big Data » (en fait, cela devient du big data quand il y a vraiment beaucoup d’exemples. Notez aussi que ce terme est en voie de désaffection car en sciences aussi, il y a des modes…Je vous le présente pour que vous ne soyez pas perdus si vous le croisez)
Notez également que l’on ne peut pas visualiser réellement des exemples dans des espaces de dimension supérieure à 3. Ceci ne nous empêche pas de réfléchir et de calculer dans ce type d’espaces.
Apprentissage supervisé et non supervisé
Si les problèmes d’apprentissage automatique consistent toujours à apprendre à réaliser une tâche à partir d’exemples, on divise traditionnellement ces problèmes en deux catégories : apprentissage supervisé et apprentissage non supervisé.
On parle d’apprentissage supervisé lorsque chaque exemple est accompagné de la bonne réponse attendue.
Les applications de classification et de régression vues auparavant entrent dans ce cadre.
On parle d’apprentissage non supervisé lorsque chaque exemple n’est pas accompagné de la bonne réponse attendue.
C’est le cas par exemple du clustering vu avant. Il existe d’autres tâches non supervisées, qui ne seront pas abordées dans ce cadre. On peut noter aussi qu’il existe de l’apprentissage semi-supervisé, dans lequel les algorithmes essayent d’apprendre à prendre une bonne décision, en prédisant eux mêmes la bonne réponse. Ce point ne sera pas non plus abordé dans ce cours, ou nous nous concentrerons sur les problèmes les plus classiques.
Apprentissage / Inférence / Bases d’exemples.
Ici encore, un peu de formalisation sur les phases de l’apprentissage automatique, et la nécessité de disposer d’au moins deux bases d’exemples.
Apprentissage et Inférence
Un programme d’Apprentissage supervisé, on l’a dit, doit apprendre, à partir d’exemples dont la réponse attendue est connue, à prendre une décision pour des exemples dont la réponse est inconnue.
On distingue donc deux phases bien distinctes, lors d’un apprentissage automatique.
- Tout d’abord, une phase d’Apprentissage pendant laquelle le programme apprend à partir des exemples qu’on lui a donné.
- Lorsque l’on souhaite prendre une décision sur un exemple, on parle d’une phase d’inférence.
Dans le cas d’un algorithme du plus proche voisin, il n’y a pas à proprement parler de phase d’apprentissage. Pour bien que vous compreniez ce concept, nous allons modifier notre algorithme de reconnaissance de sexe en fonction de la taille et du poids. Nous voudrons que :
- une première phase extraie des informations de la base d’exemples (phase d’apprentissage)
- une seconde phase (phase d’inférence) prenne la décision en se basant exclusivement sur :
- le vecteur de caractéristiques de l’objet inconnu
- les informations apprises en phase 1.
Je remets ci dessous la figure du nuage de points de notre base d’exemples :
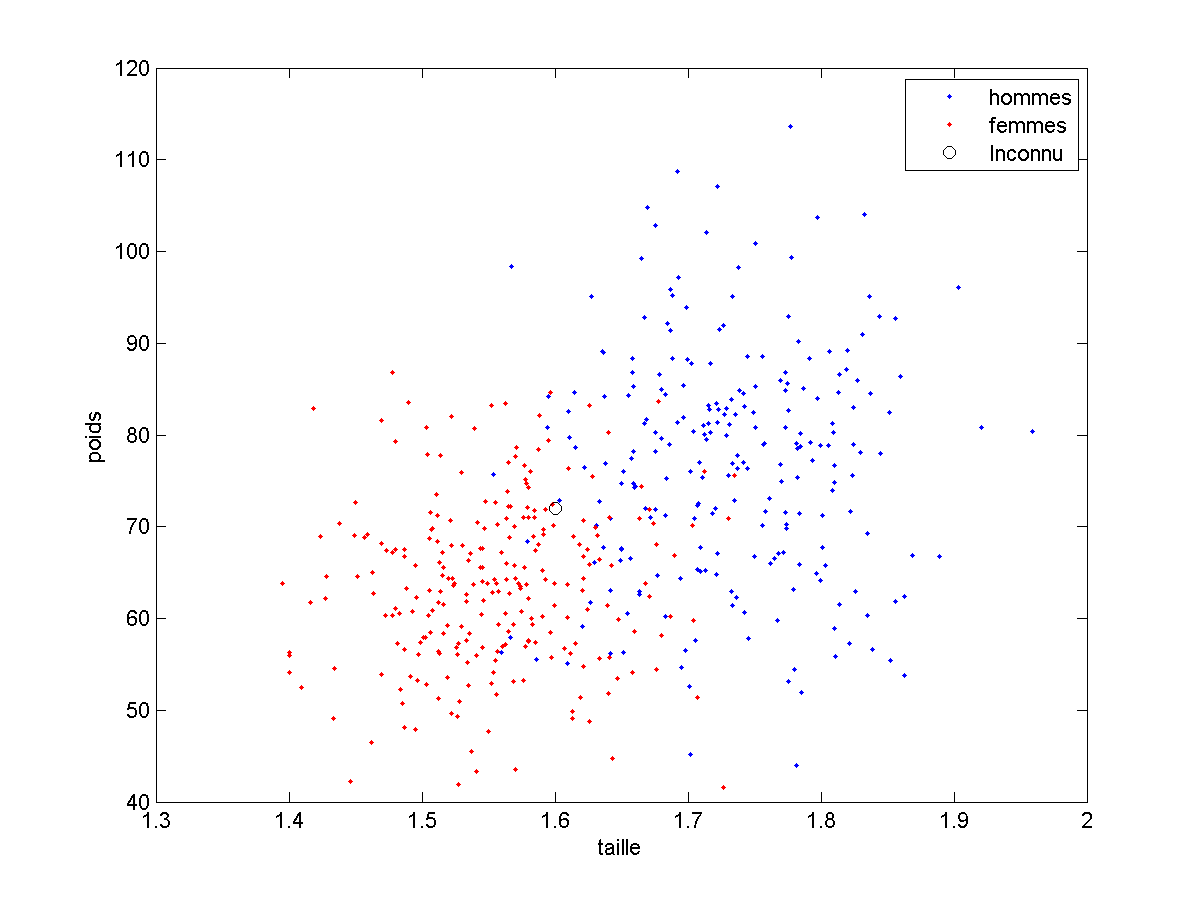
Une des façon d’extraire des informations à partir des exemples est de ne retenir que ce qu’est un « homme moyen » et une « femme moyenne », ce que je peux faire en calculant le barycentre de chacune des classes. Ce sont les cercles rouges et bleus de la figure ci-dessous.
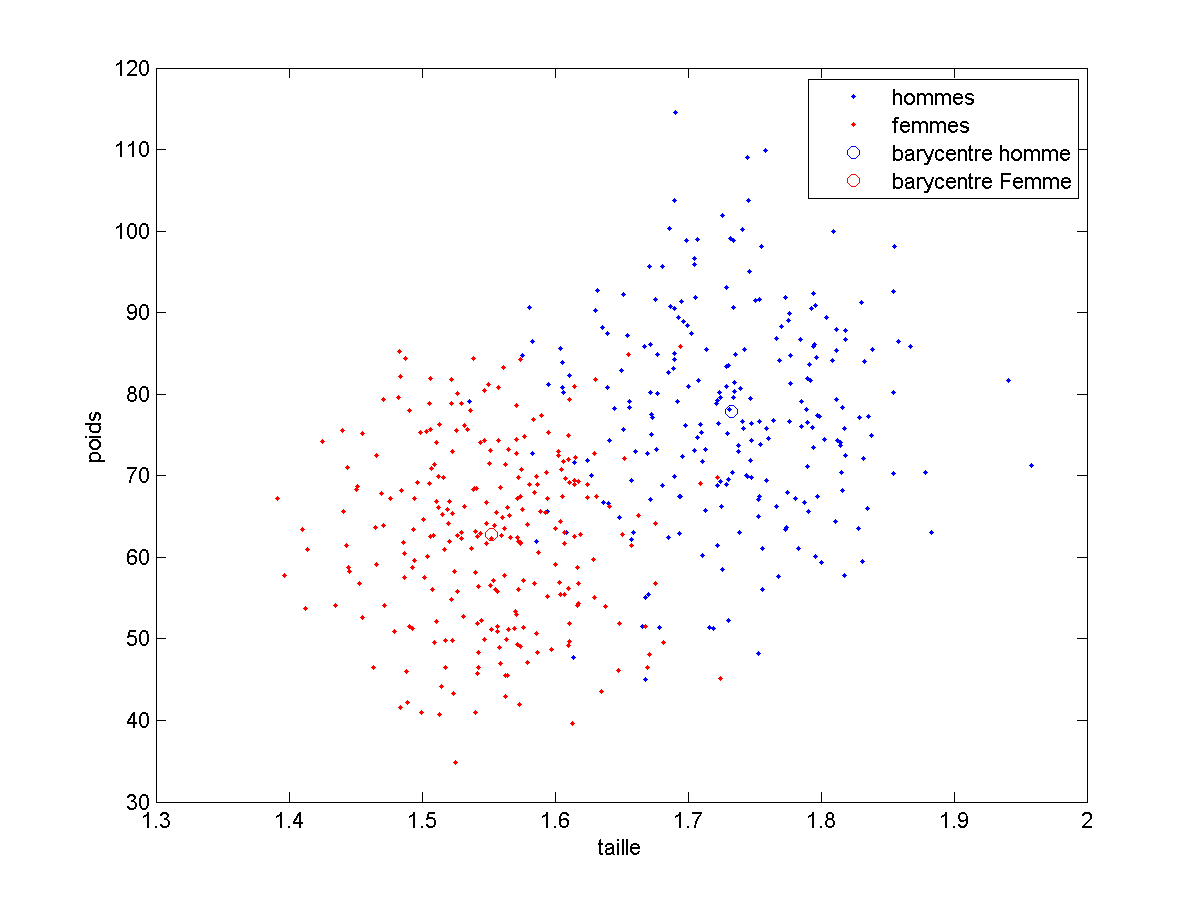
Notre phase d’apprentissage, ici consisterait simplement en ce calcul de barycentre. Ce calcul effectué, il est alors très rapide de comparer un vecteur de caractéristiques à ce que nous avons retenu :
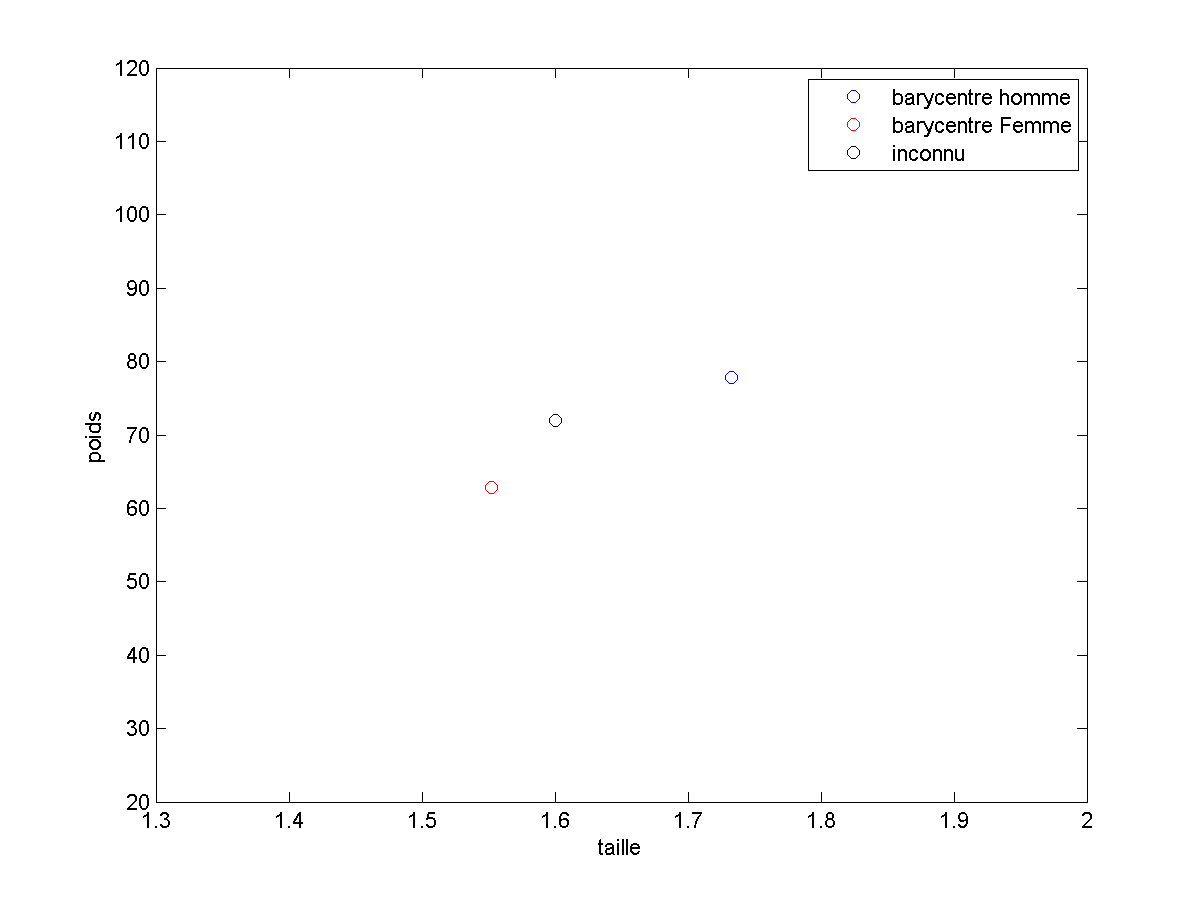
Dans ce cas précis :
- la phase d’apprentissage est un calcul de moyenne ;
- la phase d’inférence compare le vecteur inconnu à ces moyennes (et peut choisir le plus proche).
On est éventuellement près a passer beaucoup de temps à apprendre, si une fois appris, le temps de prise de décision est très réduit.
Comparez par exemple la complexité des opérations pour un algorithme du plus proche voisin (ppv) et notre nouvel algorithme lors de la phase d’inférence, sur notre problème si l’on dispose de 10 000 exemples (et deux classes).
- ppv : la complexité est en O(10 000). Il faut, pour chaque prédiction à faire, scruter les 10 000 exemples, trouver le plus proche de la situation à traiter et prendre la même décision.
- nouvel algorithme : la complexité est en O(1). Il faut, pour chaque prédiction à faire, trouver le centre (parmi les deux possibles) le plus proche de la situation à traiter et prendre la même décision.
C’est d’ailleurs une des grandes limites des algorithmes type ppv ou k-ppv
Il est par ailleurs possible d’apprendre tout un tas d’autres choses. Nous aurions pu, par exemple, apprendre les paramètres de la droite séparant au mieux les exemples.
Un algorithme d’apprentissage automatique, c’est ainsi un modèle permettant un calcul d’inférence. La phase d’apprentissage permet de fixer les paramètres du modèle pour qu’il soit aussi efficace que possible.
Dans l’exemple, simpliste, présenté ci dessus, notre classifieur cherche, pour prédire la classe d’un point, quel est le barycentre le plus proche. Cela revient à tracer la bissectrice de nos deux barycentres, puis à regarder de quel côté se trouve le point dont on veut connaitre la classe. Le modèle de notre classifieur est donc une droite, dont les paramètres (pente et ordonnée à l’origine) sont appris lors de la (petite) phase d’apprentissage par la détermination des barycentres. Nous verrons plus loin des cas plus complexes d’apprentissage.
base d’apprentissage / base de généralisation
Nous avons vu que l’apprentissage nécessitait des exemples dont la réponse est connue, de façon à apprendre les paramètres du modèle. Avant de pouvoir utiliser notre algorithme en conditions réelles, il serait bon d’évaluer ses performances.
Si on évalue ses performances sur les exemples sur lesquels l’algorithme a appris, nous allons sur-évaluer ses performances réelles. (Comme si en partiel, on vous posait exactement les mêmes questions que celles vu en TD. Votre note ne reflètera pas votre capacité a généraliser les techniques vues en TD).
De ce fait, il faut impérativement séparer la base d’exemples dont on dispose en deux sous-bases (minimum) :
-
la base d’apprentissage contenant les caractéristiques des exemples et leur réponse attendue, qui servira à l’algorithme lors de la phase d’apprentissage. On pourra évaluer sur cette base ses performances en apprentissage.
-
la base de généralisation appelée aussi parfois base de validation (voir base de test, mais ce terme prend parfois un autre sens), qui contient également les caractéristiques des exemples et leur réponse attendue mais pour des exemples que l’algorithme n’a jamais vu lors de l’apprentissage. Cette base servira pour évaluer la capacité de l’algorithme à généraliser ce qu’il a appris sur de nouveaux exemples. Les performances mesurées sur cette base sont appelées performances en généralisation et évaluent les performances attendues de l’algorithme en utilisation réelle.
Nous verrons plus loin, de façon précise, comment effectuer cette séparation en deux bases, au mieux.
Mise au point des algorithmes
Compte tenu de ce qui précède, le développement d’un algorithme d’apprentissage automatique suit à peu près les trois phases suivantes, dans cet ordre :
- phase d’apprentissage (sur la base d’apprentissage)
- évaluation des performances en généralisation (sur la base de validation). Si ces performances sont correctes, on passe à la phase 3.
- mise en place opérationnelle sur des exemples dont on ne connait pas la bonne réponse. C’est la phase de prédiction.
Voyons donc maintenant un peu plus précisément cette notion d’évaluation de performances.
Evaluation de performances
L’objectif de l’apprentissage automatique est d’essayer de construire des algorithmes aussi bons que possible pour un problème donné. Il sera donc nécessaire d’évaluer les performances de nos différents algorithmes. Nous verrons dans la partie Apprentissage par optimisation que l’on cherchera les paramètres du modèle permettant d’obtenir les meilleures performances. C’est sur cette notion que je vais me pencher maintenant, en me concentrant sur un problème de classification.
Quand on cherche “la meilleure solution à un problème”, quel qu’il soit, il est extrêmement utile de disposer d’une mesure permettant de quantifier la qualité d’une solution donnée. Ainsi, si je dispose de deux solutions possibles, si je peux mesurer leurs qualités respectives, je peux privilégier l’une ou l’autre de ces deux solutions.
Première mesure de performance : la probabilité d’erreur.
Ici, une solution est un algorithme donnant des prédictions pour chaque exemple de la base. La question qui se pose est donc : Comment mesurer la qualité d’un algorithme de classification. Ou encore, si j’ai deux algorithmes, lequel est le meilleur ?
Une réponse raisonnable est : *Celui qui, en moyenne sur de nombreux exemples, a le plus souvent raison. Ceci est complètement équivalent à : celui qui, en moyenne, se trompe le moins. Si l’on dispose d’un algorithme et d’une base d’exemples avec leurs classes associées, nous avons donc une première mesure :
En classification, une mesure de performances intéressante sur une base d’exemple est simplement le nombre moyen d’erreurs de classification de notre algorithme sur ces exemples. Ce chiffre est assimilable à une probabilité d’erreur.
Une autre mesure possible serait bien évidemment la probabilité de classification correcte qui est la probabilité de reconnaître correctement un exemple.
Ces deux mesures sont équivalentes. Simplement, on essaiera d’obtenir l’algorithme avec la probabilité d’erreur moyenne la plus faible. Cet algorithme aura également la probabilité de classification correcte la plus haute parmi tous les algorithmes possibles.
Nous verrons dans les pages de niveau 1 d’autres mesures de performances, pour la classification ainsi que pour d’autres problèmes, mais restons en pour le moment à la probabilité d’erreur.
Introduction au sur-apprentissage
Nous l’avons dit, nous pouvons mesurer les performances :
- lors de l’apprentissage : on calcule la proba d’erreur sur les exemples de la base d’apprentissage. Cela nous permet de dire à quel point notre algorithme est bon sur des exemples qu’il a déjà vus ;
- lors de la validation : on calcule la proba d’erreur sur les exemples de la base de validation. Cela nous permet de dire à quel point notre algorithme est bon sur des exemples qu’il n’a jamais vus.
Ce sont bien ces performances en validation qui permettent de savoir si notre algorithme est suffisamment fiable pour passer en phase de prédiction.
On distingue trois cas possibles. Si notre algorithme a :
- des performances en validation légèrement inférieures aux performances en apprentissage, tout va bien jusque-là.
- des performances en validation très inférieures aux performances en apprentissage, vous avez vraisemblablement un problème de sur-apprentissage (ou overfitting en anglais). Ce cas est tellement courant qu’il fait l’objet d’une section dédiée.
- des performances en validation supérieures à ses performances en apprentissage, c’est bizarre. Votre programme est sans doute buggé ou bien vous avez un problème dans la base d’exemple, ou encore vous avez mal séparé votre base d’exemple.
Je pense que ce qui précède est facile à comprendre vu que n’importe quelle intelligence (artificielle ou non) s’en sort souvent mieux sur les exemples qu’elle a déjà vu que sur de nouveaux exemples.
Un autre problème majeur est le suivant. Admettons que mon algorithme ait atteint les probabilités de classifications correctes suivantes : 0.79 en apprentissage, 0.75 en généralisation. Est il bon ou pas ? En d’autres termes, quelles performances peut-on atteindre avec un algorithme de machine learning ? Ce point est délicat et implique, notamment, la notion de difficulté intrinsèque du problème et de complexité du modèle.
Tous ces points (détection et lutte contre le sur-apprentissage, complexité du modèle, difficulté du problème) seront détaillés plus loin . Ici, ce qui m’importe, c’est que vous commenciez à vous familiariser avec ces questions.
A retenir
Dans ce chapitre, nous avons vu un certain nombre de notions importantes concernant l’apprentissage automatique. Ces notions seront considérées acquises pour la suite de ce cours. Pour vous aider à vérifier que vous les maitrisez, voici un bref résumé dont vous devriez être en mesure de comprendre chaque partie :
Pour prendre une décision sur un exemple, les algorithmes s’appuient sur des informations numériques, regroupées dans le vecteur de caractéristiques.
Classification et régression sont des tâches d’apprentissage supervisé (où la bonne réponse est connue, pour chaque exemple. On appelle parfois cette bonne réponse le label de l’exemple). Le clustering, quand à lui, est une tâche d’apprentissage non supervisé (la bonne réponse n’est pas fournie avec chaque exemple).
Pour les algorithmes d’apprentissage supervisé, on distingue deux phases :
- une phase d’apprentissage, où le modèle modifie ses paramètres pour améliorer ses performances sur la base d’apprentissage.
- une phase d’inférence, où le modèle doit simplement, pour un exemple, prédire une réponse à partir de ses caractéristiques.
Enfin, il est important de mesurer les performances de l’algorithme. Ces performances sont mesurées sur deux bases d’exemples bien distinctes :
- La base d’apprentissage permet, on l’a dit, d’apprendre les paramètres du modèle. Les performances en apprentissage permettent de savoir si l’algorithme prédit correctement les réponses pour les exemples qu’il connait.
- la base de généralisation permet d’évaluer les performances en généralisation, qui indiquent comment l’algorithme se comporte sur des exemples qu’il n’a jamais vu. Elle indique ainsi les performances qu’on peut atteindre de l’algorithme lorsqu’il sera utilisé en production.
Enfin, pour préparer la suite, nous avons proposé une première mesure de performances utilisable pour les algorithmes de classification : la probabilité d’erreur moyenne sur un ensemble d’exemples.
Nous pouvons maintenant passer à des explications plus détaillées concernant la phase d’apprentissage, en se penchant sur le concept d’apprentissage par optimisation.