Introduction
Le grand débat : symbolique vs numérique
Depuis sa naissance vers la fin des années 1950, la recherche en intelligence artificielle est divisée en deux grands courants : l’IA symbolique et l’IA numérique (terme employé actuellement).
L’IA symbolique est basée sur la logique, considérant que l’intelligence humaine s’organise autour de ce concept.
Une de ses premières applications concernait, par exemple, la démonstration automatique de théorèmes mathématiques. On peut imaginer cela comme un ensemble d’axiomes, qu’on pourra combiner pour obtenir des propriétés, que l’on combinera entre elles pour découvrir de nouvelles choses.
Un autre exemple d’application est les systèmes experts. Très en vogue dans les années 80-90 dans l’industrie, il s’agit de composer un raisonnement permettant de répondre à des questions concernant des données à partir d’un ensemble de faits et de règles. Les faits et les règles initiaux devaient être écrits en observant le raisonnement d’un expert face à un problème donné.
Il y a eu des applications de ces systèmes en médecine, sidérurgie, banque, …
À l’inverse, l’IA numérique considère que le raisonnement humain est avant tout la conséquence de calculs numériques et va se focaliser sur ces calculs (probabilités, optimisations).
La connaissance et les décisions qui suivront vont plutôt être extraites d’exemples de situations. Les réseaux de neurones artificiels font partie de cette catégorie.
Pour bien distinguer les deux approches, diriez-vous qu’un chat, c’est…
-
un petit animal poilu à quatre pattes, qui fait miaou (version symbolique) ?
-
ça (version numérique) ?
 mais aussi ça
mais aussi ça 
Toute la difficulté vient de là. Bonne chance pour expliciter le lien entre les deux images pour la version symbolique ! Mais ne pas tenir compte de la logique sous-jacente va empêcher de reconnaître des chats, si l’on n’en n’a pas vu assez d’exemples (pour la version numérique).
Avantages et inconvénients
Dans le cas de l’IA symbolique, l’avantage est que les décisions prises sont le fruit d’une démarche logique, qui est relativement facile à suivre, même si la mise au point automatique de cette démarche a pu prendre énormément de temps.
L’inconvénient est qu’il est parfois très difficile pour les experts d’expliciter les règles qu’ils suivent. Une bonne part de nos décisions est prise sans qu’on puisse vraiment expliquer tous les sous-cas que l’on peut rencontrer, et l’intuition de l’expert, qui fait souvent sa qualité, rend le codage des règles délicat.
Dans le cas de l’IA numérique, les algorithmes se basent exclusivement sur les exemples qu’on lui fournit pour composer sa décision. Avec énormément d’exemples (au-delà de ce qu’un humain pourrait traiter), l’algorithme va extraire ses propres règles. C’est un gros avantage, puisqu’on n’a plus besoin d’expliciter les raisonnements.
En revanche, la façon dont l’algorithme prendra sa décision sera très peu comparable à la façon dont un humain aurait géré la situation. Il est donc parfois difficile de savoir pourquoi un algorithme commet une erreur et difficile de la corriger, par exemple.
Pour être tout à fait honnête, il me semble (je n’ai aucune certitude à ce sujet) qu’aucune des deux branches à elle seule ne peut proposer un modèle d’Intelligence Artificielle semblable à celle d’un être humain.
Pour vous donner un exemple, imaginons un enfant de 3 ans qui devrait trier des images d’animaux pour trier les mammifères des autres.
- Ce genre de tâche va être très compliqué à résoudre par une IA purement symbolique car il sera délicat d’expliciter comment reconnaître les caractéristiques d’un mammifère dans une image.
- Ce genre de tâche va être relativement facile à résoudre par une IA numérique (typiquement, un réseau de neurones). MAIS l’IA numérique aura besoin de voir beaucoup plus d’exemples que notre enfant de 3 ans. Montrez à un enfant 2 fois un chat, et il les reconnaît toujours, quelle que soit leur position et même s’ils sont dessinés de façon sommaire.
Ainsi, notre cerveau est vraisemblablement capable d’apprendre de plusieurs façon différentes et de mixer logique et probabilités de façon spontanée.
Pour vous donner un autre exemple, je suis incapable de vous donner la règle d’accord des participes passés des verbes pronominaux, mais je me trompe finalement rarement lorsque j’en rencontre. Ma connaissance du sujet est purement statistique (numérique). Ma mère, en revanche, peut réciter cette règle en toute occasion (symbolique). A priori, ma maman comme moi-même sommes pourtant des êtres humains, mais pour la même situation, nous avons mis en place des stratégies différentes.
De plus, la recherche en Intelligence Artificielle n’a pas forcément vocation à reproduire l’intelligence humaine, mais seulement à permettre à des machines de résoudre les problèmes qu’on leur pose. Quel que soit le modèle choisi, les deux approches ont réussi à obtenir des résultats qu’aucun humain ne pourrait égaler sur certains problèmes. Les deux approches peinent aussi à faire des choses que tout humain arrive à faire sans difficulté.
Étonnant, non ?
Le point actuel
Depuis les débuts de l’IA, on a vu une alternance entre ces deux branches en termes de performances. Ceci est le signe d’une recherche saine. Il n’y avait aucune certitude de la part des chercheurs (au moins officiellement car en fait, ils sont tous plus ou moins convaincus d’une chose ou d’une autre). Il existait seulement des pistes potentielles qu’il convenait d’explorer. Libre à chacun d’explorer ce qui lui paraissait le plus prometteur à un instant donné.
À ce jour, et depuis à peu près 15 ans, l’IA symbolique est un peu en sommeil. Les performances obtenues en IA numérique (notamment à l’aide des réseaux de neurones artificiels) ont entraîné un engouement très fort des industriels pour ces techniques. Ce qui est logique puisque, auparavant, les systèmes experts avaient été poussés très fortement jusqu’à montrer leurs limites.
Il y a fort à parier que la situation s’inverse dans quelques années. C’est déjà partiellement le cas, puisqu’on cherche actuellement à mélanger les deux approches pour obtenir des systèmes permettant d’obtenir le meilleur des deux mondes :
- un apprentissage à partir d’exemples,
- des exemples aussi peu nombreux que possibles,
- des prises de décisions plus transparentes pour un observateur humain.
Quoiqu’il en soit, ce cours sera consacré à l’apprentissage automatique vu de façon numérique. Ce préambule avait surtout pour objectif de vous signaler que ce n’est pas la seule approche possible et, en aucun cas, la seule approche légitime.
L’instant Philo : Hal 9000, Skynet, Red Queen, Jarvis et leurs amis.
Un cours d’IA sans son questionnement sur le futur des IA, et la possible disparition de l’humanité à cause de ces programmes, ne serait pas un vrai cours d’IA !
En gros, et concernant les IA basées sur de l’apprentissage automatique, on peut se poser des questions sur l’efficacité des IA, et sur les métiers qu’elle menace
Efficacité des IA :
Les IA actuelles sont extrêmement efficaces, sous quelques conditions.
- quand le problème reste dans un cadre bien défini,
- quand on dispose de très nombreux exemples.
- quand les erreurs de décision commises lors de l’apprentissage ne sont pas dramatiques
On peut ainsi créer des IA pour reconnaître des visages (les exemples abondent car les réseaux sociaux sont remplis d’exemples de photos de vous, annotées comme vous représentant). On peut aussi créer une IA qui jouera aux échecs (maintenant, le modèle standard est que l’IA joue contre elle-même pour créer des exemples à partir desquels apprendre). On pourrait, sur le même principe, faire une IA qui batte tout le monde à FIFA.
Il est un peu plus difficile de faire une IA qui conduise une voiture, car on peut difficilement gérer les erreurs que l’IA va commettre au cours de son apprentissage. Une solution consiste à entrainer l’IA à conduire une voiture dans un simulateur de conduite, dans lequel un accident ne génère aucune perte matérielle ou humaine. Encore faut il avoir un simulateur assez réaliste pour que l’IA s’y retrouve lors du passage dans la réalité.
Il est également plus difficile de créer une IA qui s’occupe d’un enfant en bas âge parce que, en plus d’éventuels drames possibles en cas d’erreurs, cela nécessite aussi d’effectuer en parallèle de nombreuses tâches relativement complexes mais surtout interconnectées :
- reconnaître l’émotion de l’enfant à chaque instant,
- moduler les activités en fonction de ces émotions.
Métiers potentiellement menacés par les IA
L’arrivée massive des IA dans l’industrie constitue une nouvelle révolution industrielle, laquelle s’accompagne de la mise en péril de certains métiers existants. Quels sont les métiers concernés en premier lieu ? Tous les métiers où la connaissance ne vient que d’exemples et où les résultats peuvent être rapidement évalués. En voici quelques exemples :
- courtier en bourse,
- médecin généraliste (ça se discute, mais si l’on définit un taux d’échec accepté, oui…),
- pilote d’engin dans des situations relativement simples (trains, tramway, …).
Inversement, les métiers où les situations sont les plus différentes d’un cas à l’autre ET qui nécessitent une certaine dextérité de manipulation sont relativement protégés. Par exemple, à ce jour, il est inconcevable d’avoir un robot plombier, car aucune installation de plomberie n’est pas la même et qu’on peut difficilement imaginer un robot capable de passer sous toutes les toilettes du monde pour y changer un joint. Il est ainsi plus difficile d’avoir un robot plombier qu’un robot chirurgien (la salle est fixe dans le cas du chirurgien).
Depuis 2014, une nouveauté (les Generative Adversarial Networks ou GAN) a même permis aux IA d’atteindre des capacités de création (en musique, arts plastiques, design, mode …). Ces IA sont capables de générer des choses nouvelles, ressemblant aux exemples qui lui sont fournis pour un résultat très bluffant. On peut donc imaginer que pour de la production de masse, ces IA remplacent rapidement toute une frange de la population d’artistes/artisans de ces domaines (ne laissant que des postes de création artistique originale).
L’IA non fantasmée
Dans ce cours, il s’agit de commencer à aborder des techniques dites d’ « Intelligence Artificielle », dans le domaine de l’Apprentissage Automatique (ou Machine Learning en anglais).
Les trois problèmes de base
Commençons par voir quels problèmes les plus fréquents nous voulons résoudre en apprentissage automatique. Ils sont au nombre de trois et sont détaillés dans les sections qui viennent.
La classification
Si, à partir d’informations bien définies et communes à tous les exemples, on souhaite reconnaître qu’un objet ou une situation fait partie d’une catégorie, on parlera d’un problème de classification.
Évidemment, à ce stade, il est délicat pour vous de comprendre ce dont je parle. Prenons donc un exemple :
Imaginons que notre programme travaille sur des personnes. Pour chaque personne, nous disposons d’informations : sa taille / son poids / le nombre de cigarettes qu’il fume par jour. Un problème de classification pourrait consister à décider si une personne est un homme ou une femme (2 catégories).
Notez bien qu’en 2022, je suis bien conscient des problèmes que pose la non binarité. Notre capacité à créer des programmes capables de réaliser efficacement cette tâche ne signifie pas du tout qu’il faudrait les utiliser dans la vie quotidienne. Cet exemple a en fait plusieurs avantages : tout le monde a à peu près une idée des différences existant en moyenne entre hommes et femmes en termes de poids, taille, hygiène de vie. Tout le monde a aussi en tête des contre-exemples générateurs d’erreurs. C’est un excellent exemple pédagogiquement.
Cette conceptualisation recouvre un grand nombre de problèmes, dont voici quelques exemples, des plus directes aux plus éloignées :
- À partir de données médicales, prédire la pathologie d’un patient parmi N possibles.
- À partir d’une photo de visage, savoir quelle est la personne représentée sur la photo. Ici, nous aurions autant de catégories que de personnes possibles.
- À partir d’une série de notes de musique, prédire la note suivante. Notez que ceci permet de composer de la musique de proche en proche.
C’est l’une des forces de cette modélisation : elle répond à une énorme variété de problèmes de la vie courante.
La régression
Si, à partir d’informations bien définies et communes à tous les exemples, on souhaite prédire la valeur associée à un objet ou une situation, on parlera d’un problème de régression.
Ici encore, un exemple sera plus parlant :
Imaginons que notre programme travaille sur des personnes. Pour chaque personne, nous disposons d’informations : sa taille / son poids / le nombre de cigarettes qu’il fume par jour. Un problème de régression pourrait consister à prédire son espérance de vie.
Voici quelques exemples de problèmes de régression pour vous donner une idée de la variété de tâches que ce problème recouvre :
- en fonction de la valeur d’une action boursière tout au long d’une période passée, prédire sa valeur le lendemain.
- à partir de vidéo et d’informations sur un véhicule, prédire la vitesse à choisir et l’angle de rotation du volant permettant de passer une courbe.
Si vous trouvez des ressemblances avec la classification, c’est normal. En gros, la classification consiste à choisir une catégorie que l’on pourrait représenter par un entier. La régression doit, elle, choisir une prédiction, souvent dans \(\mathbb{R}\) ou \(\mathbb{R}^2\) (l’action boursière)
(le véhicule).
Le clustering (partitionnement de données)
Le dernier problème est un peu différent.
À partir d’un ensemble d’objets ou de situations, on souhaite les regrouper en sous ensembles homogènes. On parle alors d’un « problème de clustering ».
Ici encore, un exemple vous aidera sans doute à mieux comprendre :
Imaginons que notre programme travaille sur des personnes. Pour chaque personne, nous disposons d’informations : sa taille / son poids / le nombre de cigarettes qu’il fume par jour. Un problème de clustering pourrait consister à chercher, parmi l’ensemble des personnes dont on dispose, à extraire deux groupes de personnes se ressemblant le plus. L’un des résultats possibles serait deux groupes d’individus, dont une analyse a posteriori montrerait qu’ils sont liés à l’hygiène de vie des personnes.
Je vais insister un peu sur une confusion commune quand on attaque le domaine de l’apprentissage automatique : la distinction entre classification et clustering.
En classification, les catégories sont prédéfinies. Le problème consiste à ranger chaque exemple qui se présente dans la bonne catégorie. En clustering, il s’agit de découvrir des catégories pertinentes. Le problème consiste à regrouper des exemples, afin d’obtenir les groupes les plus homogènes possibles.
Les application des problèmes de clustering sont également innombrables :
- En marketing, en fonction de fichiers clients, trouver les types de consommateurs associés à un produit.
- À partir de données météorologiques, trouver les types de temps existants dans une région.
- À partir de données physiologiques, définir des groupes d’animaux (refaire une classification du vivant).
Petite remarque d’importance
Éventuellement, en lisant ce qui précède, vous avez commencé à réfléchir pour concevoir vous-même un programme qui puisse, par exemple, reconnaître si une personne est un homme ou une femme (les autres problèmes sont plus complexes). Peut-être quelque chose comme (en python) :
def classify(taille, poids):
if taille > 1.73 :
return "homme"
else :
return "femme"
Dans le code qui précède, l’intelligence de votre programme vient directement de vous. Vous implémentez dans votre programme votre propre logique. L’Apprentissage Automatique ne fonctionne pas du tout comme cela. En apprentissage automatique, on dispose d’exemples, à partir desquels notre programme va apprendre, parfois longuement, comment prendre sa décision.
Ce cours est donc une façon totalement nouvelle pour vous de concevoir des programmes.
QCM d’auto-évaluation
Pour vous aider à vous y retrouver entre ces trois problèmes classiques, et avoir une idée de la diversité de situations qu’ils recouvrent, voici quelques exemples, dans lesquels je vous demande de reconnaître à quel problème la situation peut-elle être ramenée. Assurez-vous donc de lire attentivement la question et la consigne.
Question 1
Imaginons qu’on veuille faire un programme permettant de reconnaître, à partir d’une image, si l’objet présent dans l’image est un chien ou un chat ou un poney.
De quel type de problème de machine learning s’agit-il ?
- Clustering
- Classification
- Régression
Question 2
Imaginons qu’on veuille faire un programme permettant de déplacer un personnage de jeu vidéo à l’aide d’un joystick numérique.
De quel type de problème de machine learning s’agit-il ?
- Clustering
- Classification
- Régression
Question 3
Imaginons qu’on veuille faire un programme permettant de déplacer un personnage de jeu vidéo à l’aide d’un joystick analogique.
De quel type de problème de machine learning s’agit-il ?
- Clustering
- Classification
- Régression
Question 4
Vous êtes en charge d’analyser les données clients d’une chaîne de grande distribution, l’objectif étant de définir des groupes types de consommateurs, afin d’adapter la stratégie commerciale du groupe à ces clients.
De quel type de problème de machine learning s’agit-il ?
- Clustering
- Classification
- Régression
Question 5
Vous devez programmer un correcteur orthographique dans un traitement de texte.
De quel type de problème de machine learning s’agit-il ?
- Clustering
- Classification
- Régression
Premiers algorithmes
Ici, sans trop détailler, je vais essayer de vous expliquer les principes de l’apprentissage automatique et quelques algorithmes simples basés sur ces principes.
Nous cherchons à concevoir une solution pour qu’un programme apprenne, sur la base d’exemples, à prendre une décision concernant un objet ou une situation. Pour avancer dans ce problème, il nous faut impérativement une image mentale de notre problème. Qu’est-ce qui peut nous fournir une image mentale sur laquelle nous pourrons ensuite faire des calculs ? Les mathématiques.
Nous allons donc reprendre nos trois problèmes classiques sur des exemples très simples pour poser un peu de vocabulaire et essayer de faire émerger des début de solutions.
Application au Clustering
Re-simplifions notre exemple vu dans une section précédente, et intéressons-nous par exemple au problème du partitionnement de données (ou clustering) qui consiste à regrouper nos exemples en groupes (des clusters).
Nous disposons d’un ensemble d’exemples. Chaque exemple sera caractérisé par deux informations : taille et poids.
Les informations concernant un exemple sont appelées les caractéristiques du problème (features, en anglais). Dans notre exemple, ce sont la taille et le poids.
Dans le tableau qui suit :
- chaque ligne est une personne,
- sur une ligne, on trouve le vecteur de caractéristiques [taille, poids] de la personne.
Nos données ont la forme suivante :
| Taille | Poids |
|---|---|
| 1.8707 | 68.7103 |
| 1.5430 | 63.2235 |
| 1.8442 | 88.0109 |
| 1.6772 | 70.5969 |
| … | … |
| 1.6072 | 66.1378 |
Imaginons que l’on veuille répartir les personnes représentées par ces données en deux groupes (deux clusters). Avec ce tableau, je pourrais faire toutes sortes de calculs, mais je peux surtout visualiser mes données. On peut penser chaque exemple comme un point (ou un vecteur) dans un espace de dimension 2 (taille, poids). Ceci nous conduit à pouvoir tracer le nuage de points de nos exemples :
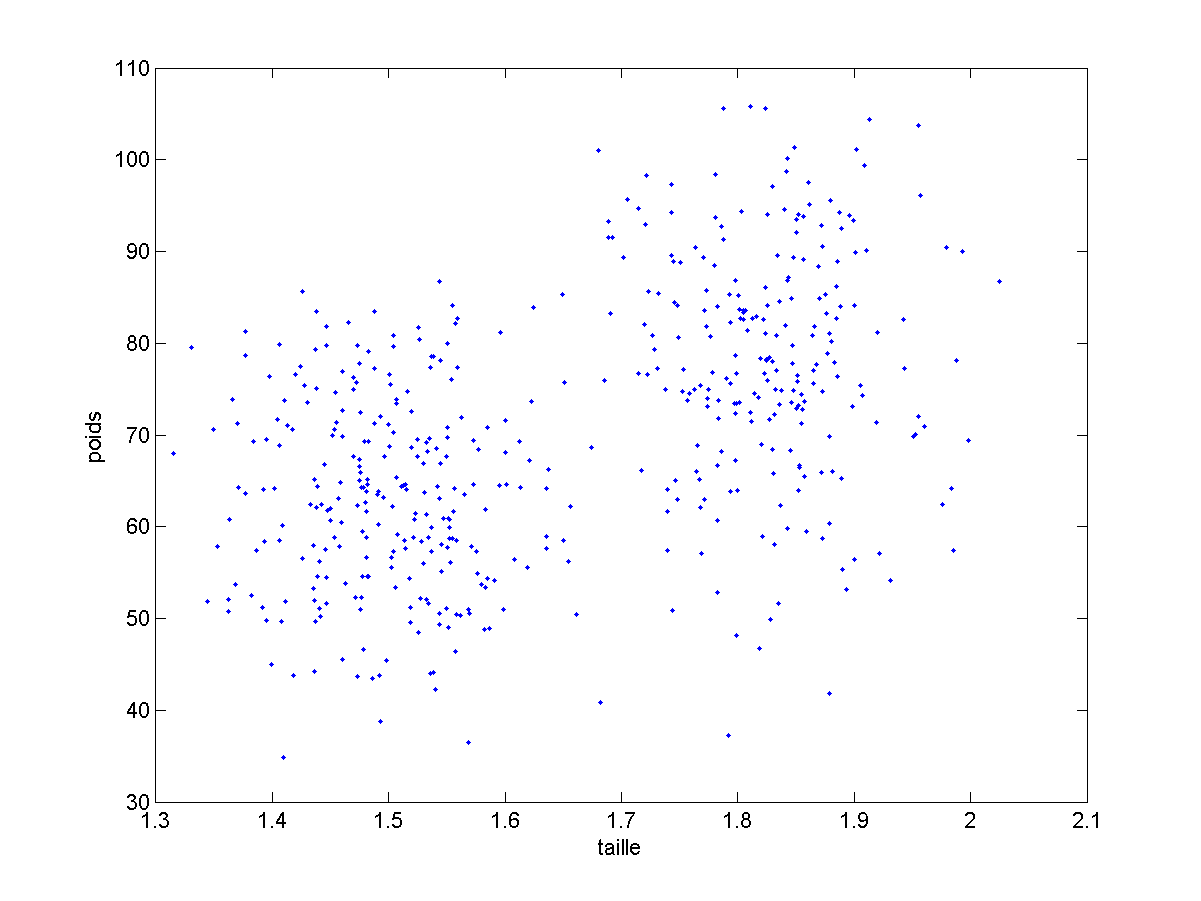
- Voyez vous deux groupes de personnes ? (Normalement, oui.)
- On ne sait toujours pas comment faire notre programme, mais au moins nous saurions répondre à la question.
Ceci montre bien l’intérêt de la visualisation des données.
Comme premier algorithme de clustering, on pourrait procéder comme suit :
- Initialement, chaque point constitue un groupe.
- Puis on cherche les deux points les plus proches et on fusionne leurs groupes. 3. On ré-itère jusqu’à ne conserver que le nombre de groupes voulu (ici, deux).
Application à la classification
Reprenons notre exemple simplifié précédent. Nous voudrions à partir d’exemples de taille et poids connus, apprendre à déduire le sexe d’un individu inconnu. Pour cela, il faut impérativement que pour chaque exemple connu, nous sachions quel est son sexe. Nos données, pour chaque exemple, indiquent donc le poids et de la taille (qui sont les caractéristiques), mais aussi le sexe de l’individu. C’est ce sexe que nous essayerons de deviner. On l’appelle le label associé à chaque exemple (ou sa classe).
Nos données prennent maintenant la forme suivante :
| Taille | Poids | Label |
|---|---|---|
| 1.8707 | 68.7103 | homme |
| 1.5430 | 63.2235 | femme |
| 1.8442 | 88.0109 | homme |
| 1.6772 | 70.5969 | femme |
| … | … | … |
| 1.6072 | 66.1378 | femme |
Il nous faudra enfin un ou plusieurs exemples inconnus à propos desquels il faudra prendre une décision : Quel est donc le sexe d’un individu dont les caractéristiques sont 1.60 , 72 ?
Encore une fois, avec ce tableau, je pourrais faire toutes sortes de calculs, mais je peux surtout visualiser mes données :
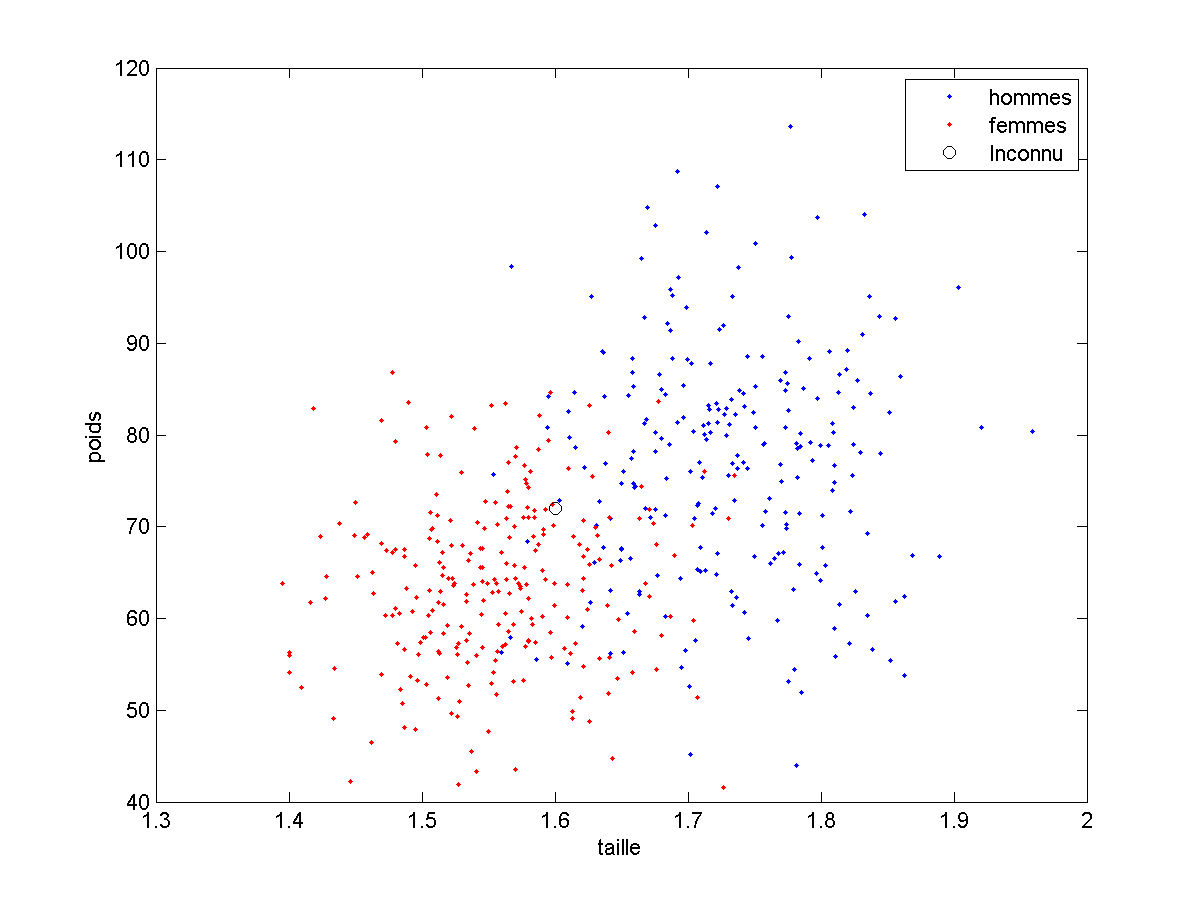
- Pouvez-vous prendre une décision concernant le point inconnu ? (Vous devriez pouvoir prédire qu’il s’agit d’une femme.)
- Pourriez -vous écrire un programme qui prenne cette décision ? (Vous pouvez penser à observer le ou les points qui lui sont proches.)
L’algorithme auquel vous avez sans doute pensé (c’est mon coté mentaliste…) est l’algorithme du plus proche voisin, qui procède comme suit :
On cherche, dans l’ensemble des points connus, quel est le point le plus proche du point à classifier. L’algorithme prend simplement la décision correspondant au label du point le plus proche.
Application à la régression
Encore une fois, je vais re-simplifier l’exemple précédent pour des questions de visualisation. Nous disposons d’exemples connus dont nous connaissons le nombre de cigarettes qu’ils fument par jour. Nous voudrions, pour un individu inconnu, prédire son espérance de vie. Pour cela, il faut impérativement que pour chaque exemple connu, nous sachions quelle est son espérance de vie. (Notez qu’ici, j’ai complètement inventé les chiffres utilisés pour mes exemples.)
Nous aurons donc des exemples connus :
| Nb Clopes | Espérance de vie |
|---|---|
| 22 | 74 |
| 0 | 45 |
| 0 | 84 |
| 22 | 51 |
| 0 | 90 |
| 10 | 72 |
| 4 | 67 |
| … | … |
| 0 | 69 |
Et nous voulons savoir quelle serait l’espérance de vie d’un inconnu qui fume, par exemple, 14 cigarettes par jour.
Encore une fois, avec ce tableau, je pourrais faire toutes sortes de calculs, mais je peux surtout visualiser mes données. Notre programme doit en fait choisir une valeur en ordonnée sur la ligne noire, d’abscisse 14, représentée dans la figure suivante.
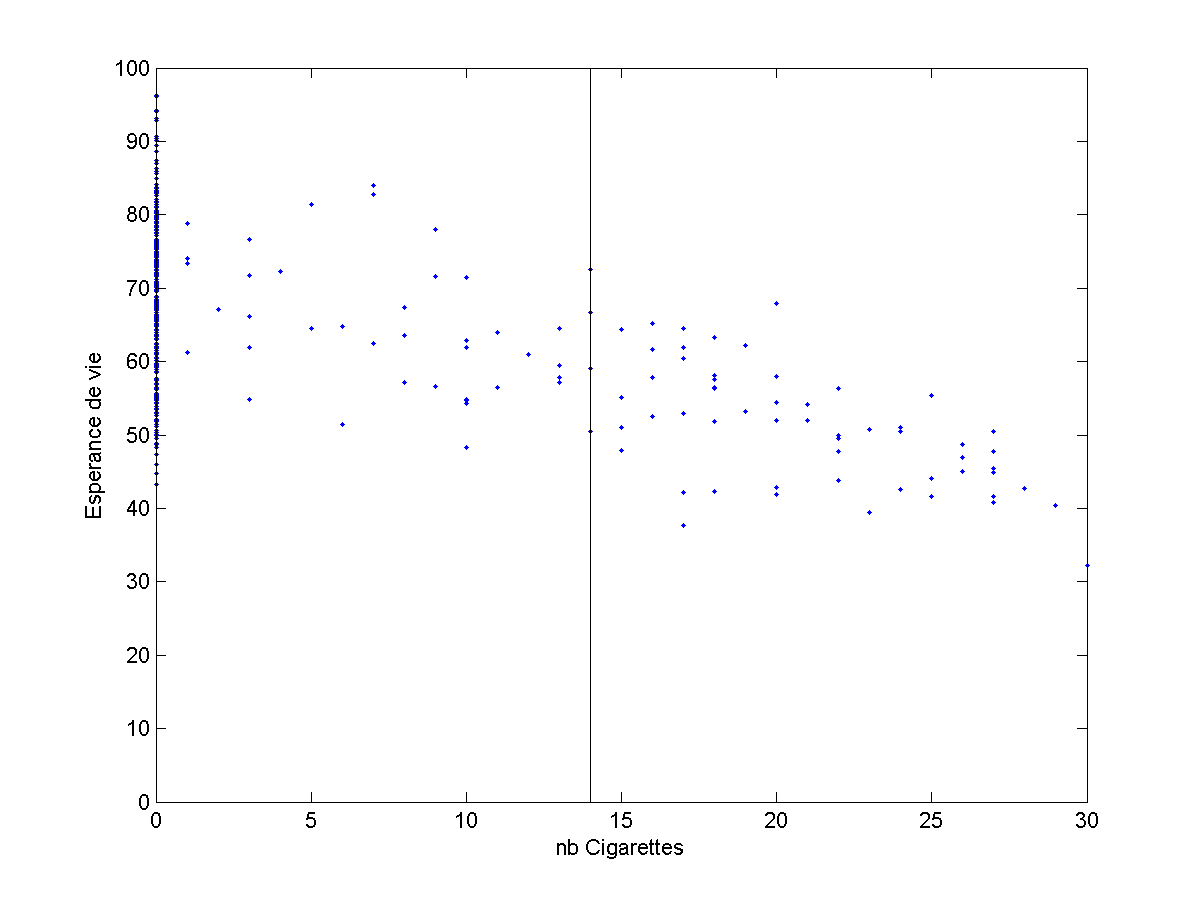
- Pouvez-vous prendre une décision concernant le point inconnu ? (Vous pourriez déduire une espérance de vie autour de 60 ans.)
- Pourriez-vous écrire un programme qui prenne cette décision ? (Éventuellement, repensez à cette idée de voisins proches.)
Si les plus matheux d’entre vous auront peut-être pensé à faire une régression linéaire pour extraire la droite la plus proche des données, je vous propose ci-dessous une version plus simple.
On cherche, parmi les exemples, tous les 5 plus proches en termes de nombre de cigarettes fumées. On prend la moyenne des espérances de vie de ces exemples.
Conclusion sur ces applications
Résumons ce que nous avons vu.
Pour que nos algorithmes s’appuient exclusivement sur les exemples qu’on leur fournit pour prendre une décision, une solution pourrait s’appuyer sur la notion de distance. Pour la classification ou la régression, pour prendre une décision sur un exemple inconnu, on peut chercher :
- Le plus proche voisin parmi les exemples connus. On prendra la même décision que celle associée à ce voisin dans notre base d’exemples ;
- Les \(k\) plus proches voisins parmi les exemples connus (\(k=3\) ou \(k=5\). On pourra combiner les décisions associées à ces voisins (moyenne ou vote).
Pour le clustering, on peut également s’appuyer sur la notion de distance et regrouper récursivement les points/groupes les plus proches jusqu’à obtention du nombre de groupes souhaités.
À ce stade, nous avons posé le contexte et vous avez quelques idées sur des solutions potentielles. Pour aller plus loin, il va falloir rendre tout cela un peu plus carré et donc formaliser un peu ces problèmes.
Notez néanmoins que, dans cette section, nous avons réussi à développer des algorithmes, certes simples, mais capables de prendre une décision exclusivement en fonction des exemples proposés, et dont la logique est totalement indépendante du problème à traiter. C’est tout l’objectif du machine learning.